
The fourth blog post in the 5-minute Papers series.
You can find me on twitter @bhutanisanyam1

This blog post is the fourth one in the 5-minute Papers series. In this post, I’ll give highlights from the Paper “To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks” by Matthew Peters et al, Sebastian Ruder et al
This paper focuses on sharing the best methods to “adapt” your pretrained model to the target task. (answering the question: “To Tune or Not to Tune?”)
Context:
Transfer learning is the methodology of transferring “knowledge” from a pre-trained model. The original model might have been trained on a slightly different task as compared to our target task. Target task is the task that we are trying to solve. For ex: Performing Text Classification, etc.
Let’s consider a quick example for better understanding, let’s assume we are trying to perform text classification. Instead of training a model to perform just that, it has been shown one could train a Language Model and then fine-tune it to perform text classification.
How is this helpful?
The “knowledge” of the English language captured by the Language Model(LM) is helpful for the model. Note that this is already a standard practice with Computer Vision related tasks.
Adaptation
Back to the original discussion, transfer learning method has 2 steps:
(Pre Training) -> Adaptation
Adaptation is when we’re using our pre-trained model to “adapt” to the target task.
Two possible approaches to performing Adaptation are:
- Feature extraction:
The pre-trained features are kept frozen (The authors have used the ❄️ emoji to denote this) and these extracted features are used in the target model. - Fine Tuned:
In this approach, the model weights are trained further on the target/new task. (The authors have used the 🔥emoji to denote this)
Approach
The authors compare ELMo and BERT as the base architectures since these are one of the best performers.
These are evaluated on 5 different tasks, utilizing several standard datasets and a comparative study of Vs is discussed:
- Named entity recognition (NER)
- Sentiment analysis (SA), and Three sentence pair tasks
- Natural language inference (NLI)
- Paraphrase detection (PD)
- Semantic textual similarity (STS)
The complete experimental details are shared in the last section of the paper, two tricks mentioned in Fine-Tuning worthy a quick mention are:
- Discriminative learning rates:
The learning rates are set differently for the layers, these are decreased as 0.4 * learning rate (of the outer layer). - Gradual Unfreezing:
Starting with the top layer, in each epoch one additional layer of weights is unfrozen until all weights are training.
Results
The results of these experiments across 7 different datasets representing different fundamental tasks are summarized in the table shown below.
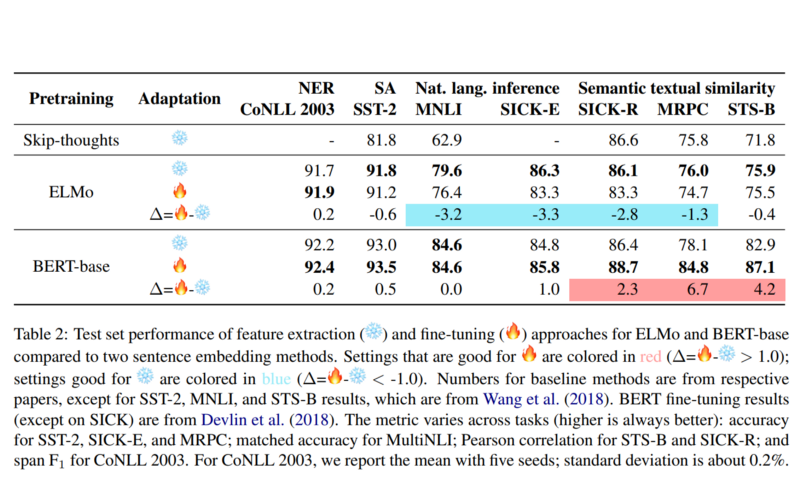
The best approach is shown by either a blue (❄️) or red (🔥) color to denote the best performer for the respective case
Conclusions and Thoughts
The paper compares the effectiveness of two specific approaches, heavily marked by Emojis (Personal Note: I found it pretty cool to see Emojis in a paper).
The paper also shares a quick practical guide for NLP Practitioners:
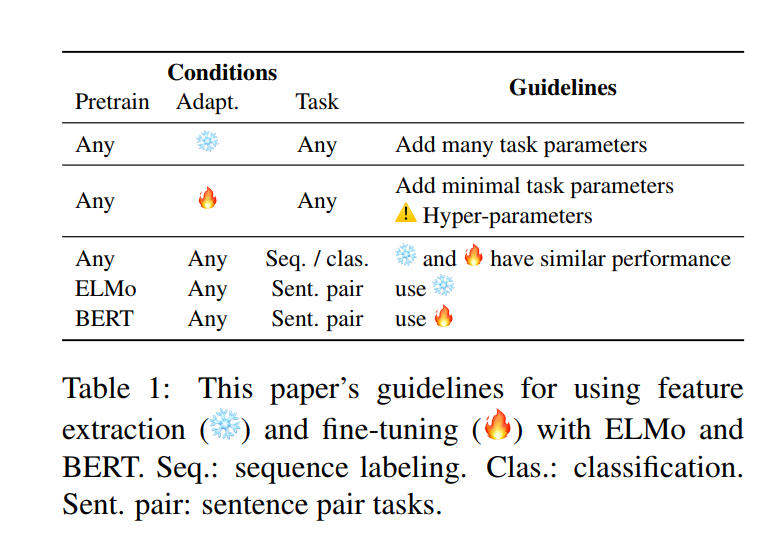
There are also extensive analyses on several tasks:
- Modelling pairwise interactions
- Impact of additional parameters
- ELMo fine-tuning
- Impact of target domain
- Representations at different layers
Both, Feature extraction being the “cheaper” or less computationally expensive option as well as Fine-Tuning, often being the better performer as it allows better adaptation of a pretrained model are important approaches.
To conclude, The paper does an extensive comparison across tasks and answers an important question. The Practitioner guideline is also an amazing table for quick reference.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science


