
The fifth blog post in the 5-minute Papers series.
You can find me on twitter @bhutanisanyam1

For today’s paper summary, I will be discussing one of the “classic”/pioneer papers for Language Translation, from 2014 (!): “Sequence to Sequence Learning with Neural Network” by Ilya Sutskever et al
TL;DR
The Seq2Seq with Neural Networks was one of the pioneer papers to show that Deep Neural Nets can be used to perform “End to End” Translation. The paper demonstrates that LSTM can be used with minimum assumptions, proposing a 2 LSTM (an “Encoder”- “Decoder”) architecture to do Langauge Translation from English To French, showing the promise of Neural Machine Translation (NMT) over Statistical Machine Translation (SMT)
Context
To highlight again, please keep in mind that the paper is from 2014, when there were no widely open sourced Frameworks such as TF or PyTorch and DNN(s) were just starting to show promise so many ideas presented in the paper might seem very obvious to us today.
The task is to perform Translation of a “Sequence” of sentences/words from English to French.
The DNN techniques expected a fixed dimensionality which was a limitation for NLP, Speech.
Approach
The paper proposes using 2 Deep LSTM Networks:
- First one acts an Encoder:
Takes your input and maps it into a fixed dimension vector - The second acts as a Decoder:
Takes the fixed vector and maps it to an output sequence.
The Model
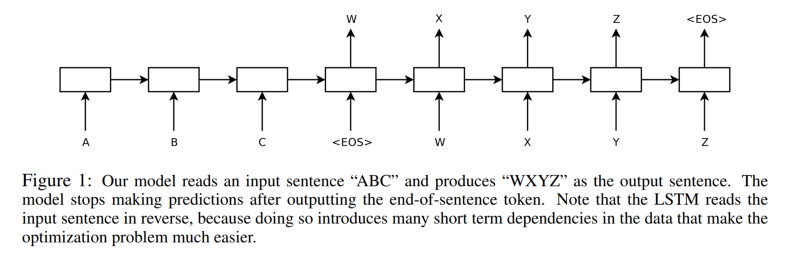
The LSTM is tasked to predict the conditional probability of a target sequence given an input sequence generated from the last layer. The generated sequence using this probability may have a length different from the source text.
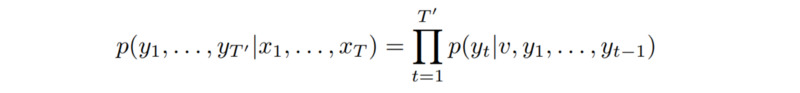
- Two LSTM(s) (Encoder-Decoder):
This allows training the LSTM on multiple language pairs simultaneously. - “Deep LSTM(s)”:
The paper mentions Deep LSTM(s) of 4 layers perform better. - Reversing the order of Input:
The paper really highlights the trick of inverting the input sequence when mapping it to the output sequence which makes it “easier for SGD” to “establish communication” between input and output.
It also enhances both short and long term predictions of the LSTM. The authors suggest that this might be due to “minimal time lag” where the distance between the generated and source words is minimized by reversing the order.
Training details:
- 160,000 of the most frequent words for the source language and 80,000 of the most frequent words for the target language. Every out-of-vocabulary word was replaced with a special “UNK” token.
- The training was done to maximize the log probability.
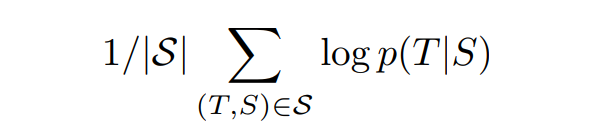
- Translations are produced using the most probable outcomes:
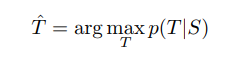
- The “Hypothesis” is created by doing a beam search which is stopped when it reaches an “<EOS>” (End Of String character)
Hypothesis are the pairs of sentences that are generated
- All of the LSTM’s parameters are initialized with the uniform distribution between -0.08 and 0.08.
- To deal with exploding gradients, the authors scale the gradients for each batch as follows:
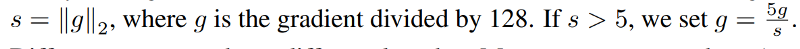
Results
- The best results are obtained with an ensemble of LSTMs that differ in their random initializations and in the random order of mini-batches.
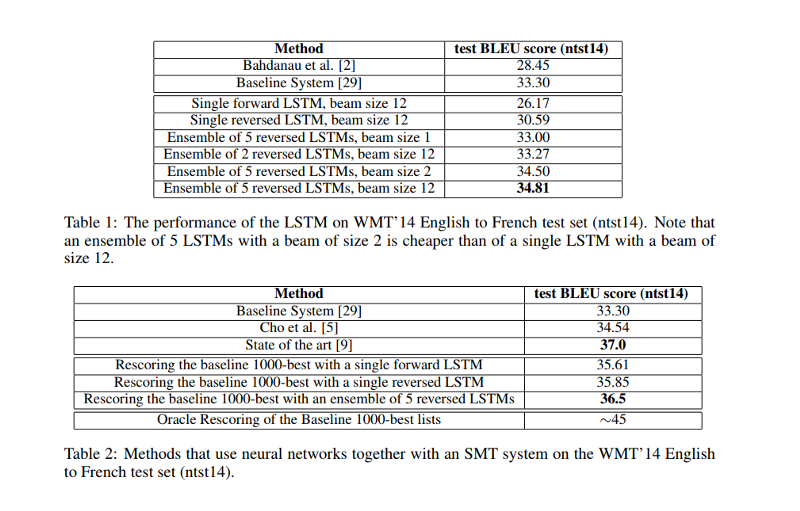
- Long Sentences: The translation showed some surprising long length results:

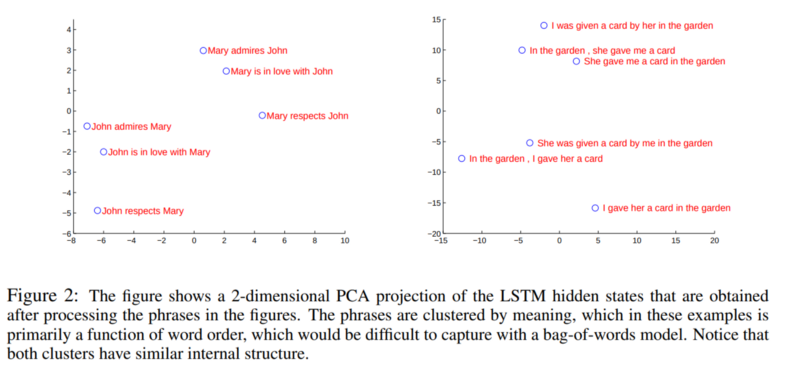
- The figure shows that the representations are sensitive to the order of words while being fairly insensitive to the replacement of an active voice with a passive voice.
Conclusion and Thoughts
- The paper was one of the first to show that DNN(s) or specifically, LSTM(s) show much promise for “Seq2Seq Learning”
- The paper also mentions the use of 2 LSTM(s), first is used to map a varying length input to a fixed length vector which then gets mapped to the target.
- LSTM(s) were shown to be surprisingly good on long sentences.
Special Thanks to Tuatini GODARD for his suggestions and proofreading. Tuatini is a Full-Time DL Freelancer. I had the chance to interview him, if you’d like to know more about him, you can find the interview here
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science


