
The third blog post in the 5-minute Papers series.
You can find me on twitter @bhutanisanyam1

This blog post is the third one in the 5-minute Papers series. In this post, I’ll give highlights from the Paper “EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks” by Jason Wei et al.
This paper, as the name suggests uses 4 simple ideas to perform data augmentation on NLP datasets. The authors have argued that their approach is much less computationally expensive and has a higher performance gain.
Context:
Data Augmentation: When you’re training a Machine Learning model, your model learns features from your dataset.
However, if you have a relatively small dataset (related to what the given model would need to be “trained”), your ML model might start to memorize features very specific to your specific dataset, this is known as overfitting.
To avoid overfitting, you can collect more data-which can pretty challenging. Or you can “augment” your current dataset to artificially add more data (free of cost). This is a well-practiced technique when you are working with Image data.
However, with Natural Language, data augmentations are not as well developed as Image domain.
Why?
Image Augmentations does not require your code to have domain-specific knowledge, its easy to crop your image or flip it.
To create more language data, which is similar to your current dataset, while retaining the original dataset details is a challenging task.
A few of the techniques that I’ll save for a future blog post are:
- Translating sentences from one language and then back to the original.
- Predictive language models to do synonym replacement.
The authors argue these are computationally expensive tasks and introduce 4 simple tasks, claiming a boost in accuracy when using EDA on “small datasets”.
Approach
- Synonym Replacement (SR): Randomly replace n words in the sentences with their synonyms.
- Random Insertion (RI): Insert random synonyms of words in a sentence, this is done n times.
- Random Swap (RS): Two words in the sentences are randomly swapped, this is repeated n-times.
- Random Deletion (RD): Random removal for each word in the sentence with a probability p.
The formula used to determine the number of sentences augmented is:
N = Alpha * Length of the sentence.
Alpha is the “augmentation parameter”, higher the alpha-more aggressive the “EDA”.
Results:
These techniques are compared on small subsets of text classification datasets using a simple CNN based and RNN architecture (Details of the architectures aren’t interesting for this writeup). The comparisons are done on the model accuracies with and without EDA.
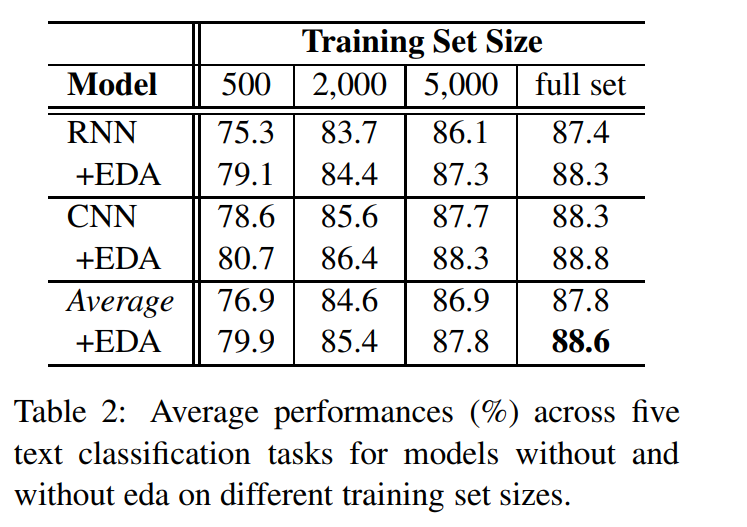
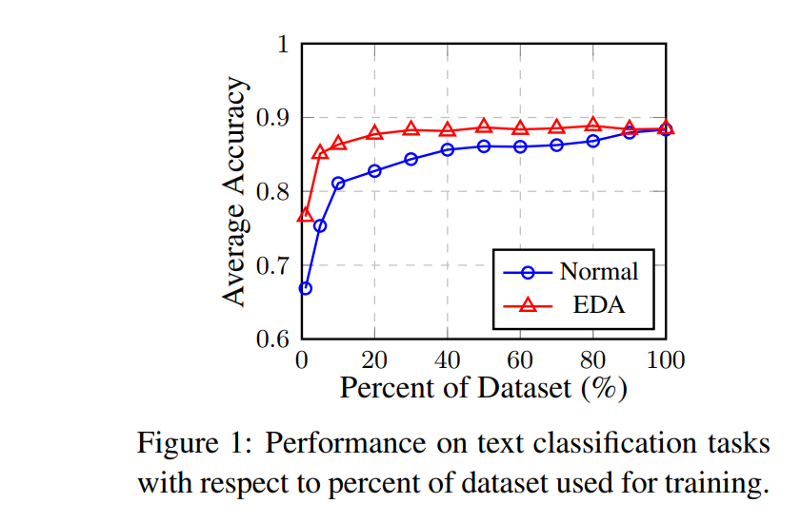
The EDA techniques are most helpful where the training set has 500 examples. The difference is less pronounced on bigger subsets. However, a slight improvement is consistent.
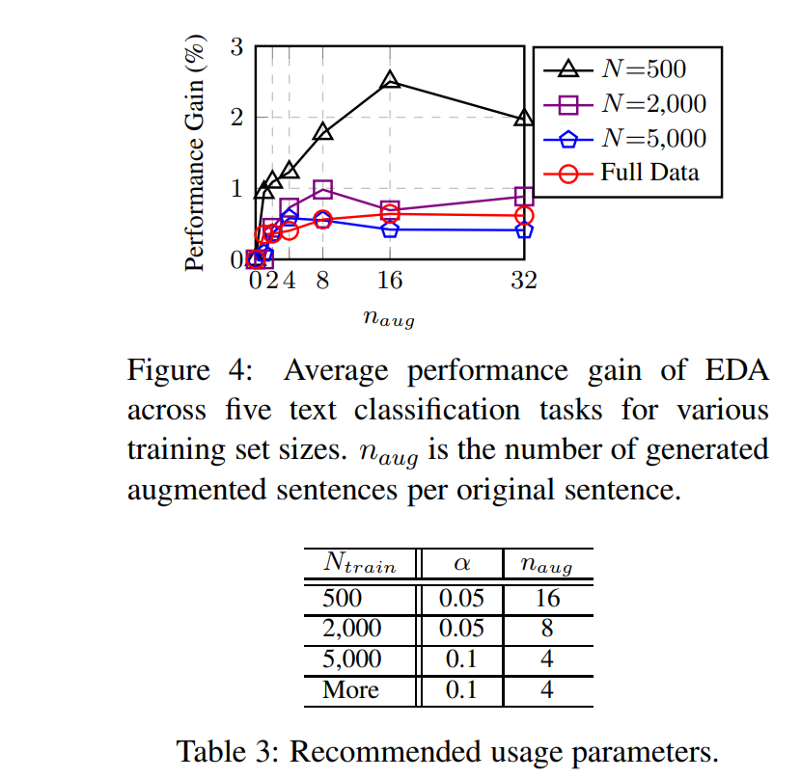
Plot comparison of performance gain against the number of augmentations applied across different subsets
Conclusion & Personal thoughts:
The techniques introduced are easy to introduce to any dataset, the authors have made the source code available as well.
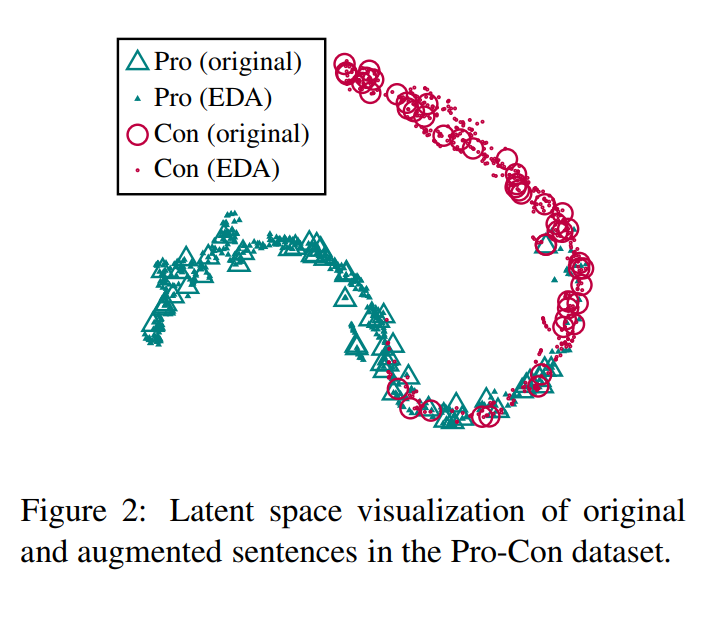
One might argue that “EDA” might change the original sentences. Authors have done a quick check, drawn Latent space visualization of original and augmented sentences in the Pro-Con dataset to prove that is not the case.
I think it might be an interesting experiment to “enable” EDA during the initial epochs of training or to start training with a subset of the datasets with EDA enabled and progressively making it less aggressive while increasing the subset portion that we’re training on.
Personally, I’m trying to run these experiments on sentiment classification. It’s a joint experiment by Rishi Bhalodia and myself. Here is the starter kernel to our approach.
As with all of my experiments, it will be based on the fastai library, you can expect a fully transparent study in future blog posts. If you’re interested in contributing, please join the discussion on fastai forums here.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science


