
1st post of the 5-minute paper’s series.
You can find me on twitter @bhutanisanyam1

About the series:
This blog post marking the start of series (Hopefully) will be a walkthrough of the ideas shared in the Bag of Tricks for Image Classification with Convolutional Neural Networks paper and a few thoughts by me.
The paper discusses a few tricks and does an analysis of their individual as well as combined contributions to training a few of the recent CNN models.
Context:
While we keep noticing a push in the State Of The Art accuracy for Image classification models and even though Deep Learning networks have surpassed human level accuracy at the task of Image Classification; these breakthroughs haven’t solely been because of the architectures or just because the Neural net models keep getting “deeper”
Many of the improvements have been due to little “tricks” that usually go unpublished or are not extremely highlighted.
The goal of the authors is to share these tricks along with extensive experiments based on each of the “trick”.
These tricks have two aims:
- Enabling better accuracy:
Tweaks to the NN models allow better accuracies. - Enabling faster training.
For ex: Utilisation of Tensor Cores on the new RTX cards using FP16 compute.
Tricks
The authors discuss a few tricks, lets go over them:
- Linear scaling learning rate:
When training a Neural Network, we feed the images into our GPU in batches, as the memory permits. These are drawn by random in SGD and have some variance to them.
As we increase the batch size, our batch to batch variance of images reduces, this allows more aggressive learning rate settings.
Learning rate is set using the formula: 0.1 x (Batch_size)/256 - Learning Rate Warmup:
When we train a Neural Net, we set the Learning Rate which determines how “fast” does the model learn or how aggressively do we penalize the predictions from it.
As we start training our Neural Network, we can expect the weights to have more randomness. If we set an aggressive learning rate, that might cause the network to diverge.
To fix this, Learning rate warmup is used which allows the learning rate to be set to lower values initially and later increased.
This is done as follows: initially learning rate is set to ~0 and then increased for the “initial batches” as per the formula:
Current epoch* (Learning Rate)/(Num_of_Initial_Epochs)
Num of initial epochs: is a hyperparameter, the number that we choose to keep until the model is “warmed up”
Learning Rate: Our final learning rate that we set for the NN. - Zero Y:
ResNets are composed of multiple Residual blocks. These can be denoted for simplicity as x+ block(x)
These are usually followed by a batch normalization layers which are further scale transformed as Y*(x)+bias. (Y and bias are “learned” as we train the network)
The paper suggests initializing for the layers at the end of ResNet blocks, Y should be initialized to 0. This reduces the number of learnable parameters initially. - No Bias Decay:
Regularisation is generally applied to all learnable parameters however, this often leads to overfitting.
The authors suggest applying Regularisation just to the convolutional and fully connected layers, Biases and batch-norm parameters are not regularised. - Mixed Precision Training:
Mixed Precision training allows us to use Tensor Cores of the recent GPU(s) which are much faster, and thereby allow us to leverage fast FP16 operations and FP32 training for calculating weights or gradients, to allow “unsafe” operations to be done in Full Precision.
For More details on Mixed Precision Training, I would suggest reading this writeup. - Model Tweaks:
The paper compares certain tweaks made to the ResNet architectures.
These include tweaking the strides inside of the Convolution layer, inspired by recent architectures. I’ll skip the details of this part since these require slightly detailed knowledge of strides and convolutions.
In general, the argument is tweaking the existing architectures also provides a boost to accuracy. - Cosine Learning Rate:
As we train our model, we can expect it to get better with epochs (Assuming everything works nicely), as our loss values decrease, we’re closing into a “minima”. At this point, we’d like to decrease our learning rate.
Instead of using Step decay where the learning rate is decayed in “steps” at fixed batch numbers, the paper suggests using a cosine scheduled learning rate as follows:
Learning Rate (Cosine_Decayed) = Initially set Learning rate * 0.5 * ( 1 + cos( Current_Batch * (Pi))/Total_Num_Batches)) - Label Smoothing:
This suggests tweaking the final the final layers and the probability distribution for the predictions to allow the network to generalize better. I’ve skipped the details of how this is implemented. - Knowledge Distillation:
This approach “Distills” the knowledge from another pre-trained “teacher” model into our current student network.
This is done by adding a distillation loss that penalizes our student network based on how much its predictions are off when compared to the “teacher model”.
Results:
The paper shows the most promise in ImageNet, using the ResNet 50 model which shows the highest improvement.
There is an extensive study of how useful or “hurtful” each of these individual tricks is towards a task.
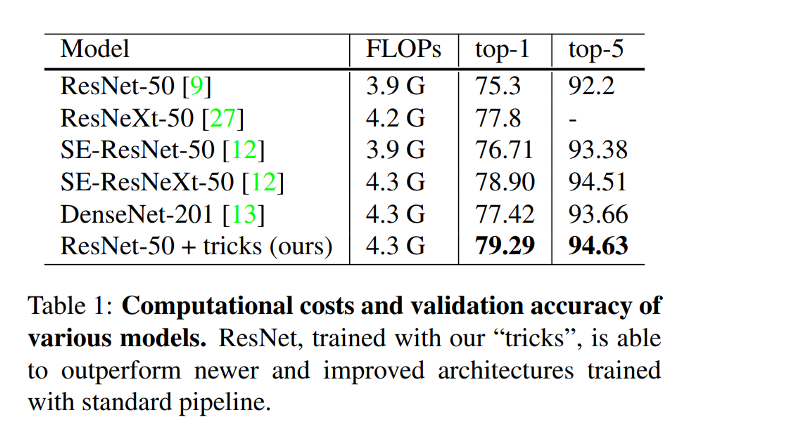
Finally, there is a comparison of using transfer learning on two tasks:
- Object Detection on the Pascal VOC dataset:
- Semantic Segmentation
Conclusion & Personal thoughts:
This is one of the first papers to embrace the little tricks that are usually not in the spotlight or not given as much importance in papers.
The paper does a deep-dive into all of the ideas, showing extensive comparisons.
As a little exercise, I believe it should be a good experiment to try a few of these tricks onto a personal target task and document the improvements.
I’d also love to read more about such tricks in future papers or have a detailed section dedicated to such approaches.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science


