
Part 2 of the 5-minute paper's series.
You can find me on twitter @bhutanisanyam1
Note of thanks: I’d like to thank Aakash Nain for providing valuable suggestions with the draft. If you’d like to know more about him you can read his complete interview here that I had the honor of doing.Edit: Special Thanks to Francisco Ingham for his suggestions as well. Francisco is also doing a Paper summary. Please check it out on his medium profileif you’re interested.
I’d also like to thank Alexandra Chronopoulou, First Author of this paper; for providing me clarifications about my questions from the paper.

This blog post is Part 2 in the 5-minute Papers series. In this post, I’ll give highlights from the Paper “An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models” by Alexandra Chronopoulou et al.
This paper discusses a few tricks and a simple approach to applying Transfer Learning from Pretrained models. They compare their approach with recent publications and claim competitive results with SOTA.
This post aims to discuss the context of the task, as well as 5 of the model details that the authors have shared which are “embarrassingly simpler” when compared to similar transfer learning approaches.
Context:
Transfer Learning in NLP involves using a pre-trained Language Model to capture information about a language and then fine-tune this model towards a goal task.
Why Transfer Learning?Instead of training from scratch, Transfer Learning allows us to leverage a model that is already good at Language modeling and then use it for our Target task such as Sentiment Analysis.
Wait, What is Transfer Learning?
Transfer learning is a technique where we leverage a model that has been already trained to do a task. For ex: Classify Images into categories (ex: ImageNet), we then use the “Knowledge” that this model has captured and then “fine-tune” or apply it to our target task. For ex: Using the ImageNet model to become an expert in detecting HotDog or NotHotDog images
However, while this approach has shown much promise there is still room for improvements.
Issues Addressed:
A few of the shortcomings of current approaches that the authors have tried to address are:
- Computationally expensive
- Sophisticated Training Techniques
- Catastrophic Forgetting
Approach
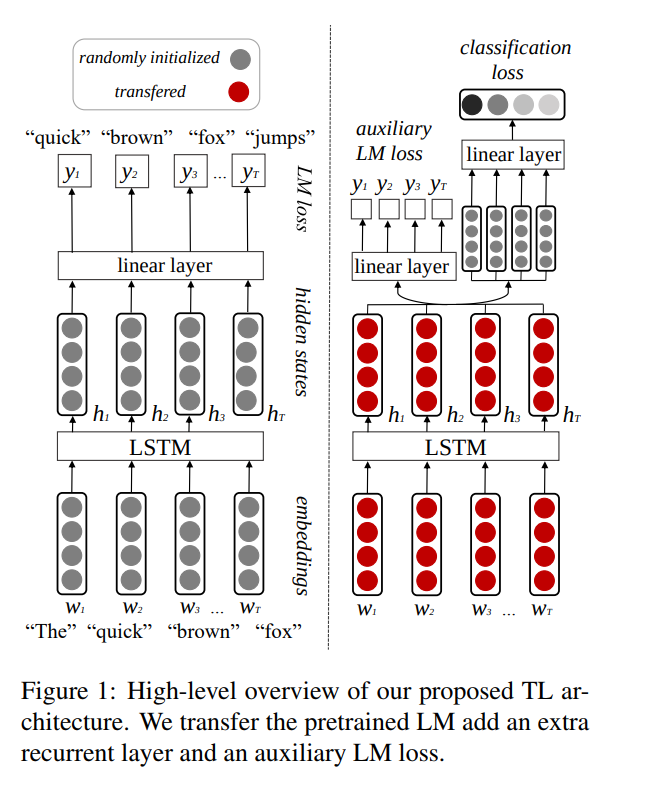
The authors have introduced their approach as SiATL:
Single-step
Auxillary
Loss
Transfer
A Language Model is trained on 20 million English Twitter messages, which is then evaluated on 5 different datasets for a different task.
There are 5 techniques or nuggets that the authors have used for training which simplify the transfer learning approach while showing performance gains:
- Pre-trained Language Model:
To get started, we need a language model.
A word-level language model is trained where the negative log-likelihood loss is minimized. - Transfer & auxiliary loss:
Instead of using a single loss value for optimization, the architecture accounts for 2 losses: an auxiliary loss as well as loss from the language model.
When training the modified pre-trained model to the target task, the authors do a weighted sum of the loss from the pre-trained LM and “auxiliary loss”
Loss = Loss(Task) + Y*Loss(Language Model)
Y is the weight parameter, it allows the model to adapt to the auxiliary task better while retaining the knowledge from the pre-trained model.
“Task-specific layer’’ is just the new RNN layer that is added for classification tasks (figure above, right part, grey layer).
So, in the second step, along with the language model loss the classification loss on top of the “task-specific” layer is also calculated.
They are both cross-entropy losses. The weighting parameter is at the same time introduced to control how much the LM affects the classification task. (which is after all our target).
This is helpful compared to using a single loss value as it allows us to leverage the “knowledge” from the language model trained initially and later give more weight to our added “layers” to the base model, for the respective target task. - Exponential decay of Y:
To fine-tune the pre-trained model to the target task, Auxiliary layers are added on top of the pre-trained model.
However, these layers are initially “untrained” and might contribute to the loss more. To avoid this and let the pre-trained model guide the training process, we set a high value for Y and then decay it as we train our model.
This allows controlling the contributions of the LM to the final loss. Intuitively, initially the “auxiliary” layer is untrained and the LM should contribute more to the loss. As the auxiliary layer gets trained, we reduce the contributions of the Language model by exponentially decaying it. - Sequentially Unfreezing:
The final model will have a few “layer” of neurons: These will include the pre-trained and fresh layers added on top of it.
Instead of training the complete model at first, a sequential unfreezing approach is followed, this is done in 3 steps.
Initially, just the auxiliary layers are trained.
Further, the model is unfrozen and trained until k-1 epochs (k is a hyperparameter)
Finally, the embedding layers are unfrozen and trained till convergence.
This approach is useful as initially, we do not want to disturb our pre-trained model and only fine-tune the “fresh” layers that we have added for the target task. Once the loss for the “fresh” layers has improved, then we would like to further improve our initial model by fine-tuning it. Once this is achieved, to push the accuracy the initial layers are unfrozen and hence the complete model is trained. - Optimizers:
The optimizers are switched when doing the training.
Initially, SGD (Stochastic Gradient Descent) with a small learning rate is used which helps to train the LM while avoiding “catastrophic forgetting”
When fine-tuning this to the target task, Adam: is used when training the model to adapt to the target task, since we’d like the LSTM and softmax layer to train fast in order to adapt to the target task.
Results:
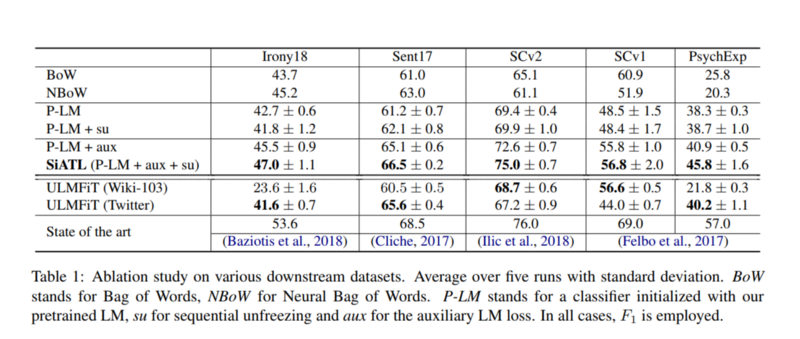
Here is the comparative study of the authors’ approach compared against 5 other approaches of Transfer Learning on NLP, across 5 datasets.
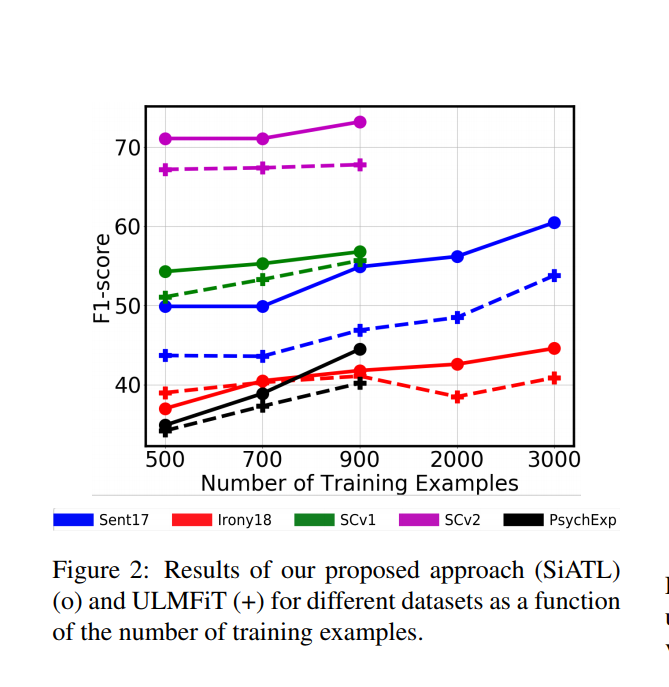
The authors have also shared a comparative study of their approach Vs ULMFiT on different training dataset sizes, showing very promising results on smaller dataset sizes.
Conclusion & Personal thoughts:
The paper has discussed a few simple approaches and offered very competitive results against other Transfer Learning Techniques.
Especially, on smaller data-sub sets, this approach (as per the claim) even outperforms ULMFiT.
I’ve particularly liked the idea of defining an auxiliary loss. At the same time, doing Sequential Unfreezing: Something that I’ve learned in the fast.ai MOOC when working with Image tasks is another great idea highlighted in the paper. Intuitively, it might help with faster convergence.
On the contrary, I do not think that ULMFiT uses a “sophisticated” learning rate schedule, I think deploying the same along with the ideas in this paper would help with even faster convergence.
As a personal experiment, I’d definitely try out these approaches on smaller subsets of IMDB along with the one cycle scheduler from the fast.ai library.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science


