
You can find me on Twitter @bhutanisanyam1
You can find the Markdown File Here
You can find the Lecture 1 Notes here
Lecture 2 Notes can be found here
Lecture 3 Notes can be found here
Lecture 4 Notes can be found here
These are the Lecture 4 notes for the MIT 6.S094: Deep Learning for Self-Driving Cars Course (2018), Taught by Lex Fridman.
All Images are from the Lecture Slides.

Applying DL to understanding Sense of Human Beings
Focus on Computer Vision.
How can we use CV to extract useful information from Videos (in Context of Cars)

Deep Learning for Human Sensing:
Using CV, DL to create systems that operate in the real world.
Requirements (Ordered according to importance):
- Data:
Enormous amounts of real data is required. Data collection is the hardest and most important part. - Semi-Supervised:
The raw data needs to reduced to meaningful representative cases, raw data needs to be annotated.
We need to collect data and use semi-supervised techniques to find pieces of data that can be used to train our networks - Efficient Annotation:
Good annotation allows good performance.
Annotation techniques for different scenarios are completely different. ex: Annotation tools for glance classification Vs Annotation for Body Pose Estimation Vs Image Pixel level labelling for SegFuse - Hardware:
Large amount of data needs large scale distributed compute and storage. - Algorithms:
We want algorithms that can self calibrate, allowing generalisation. - Temporal Dynamics:
Current algorithms are majorly image based Vs Temporal/Sequence based.
Takeaway: Data Collection, cleaning is more important than algorithms.
Human Imperfections
- Distracted Driving:
3,179 people were killed and 431k+injured in crashes involving distracted driving during 2014. - Eyes off the road:
5 seconds is the average time, your eyes are off the road while texting. - Drunk Driving:
Accountable for 31% of the traffic fatalities of 2014. - Drugged Driving:
23% of night drivers are drugged drivers (2014). - Drowsy Driving:
3% of all traffic fatalities involved a drowsy driver.
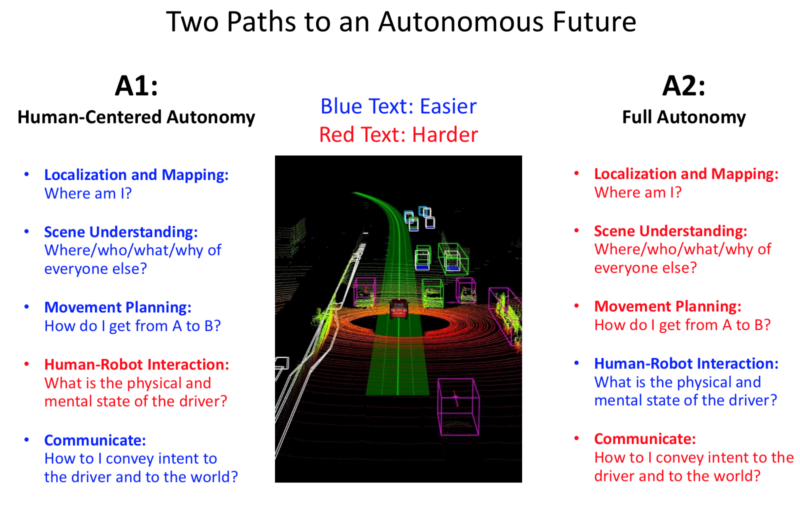
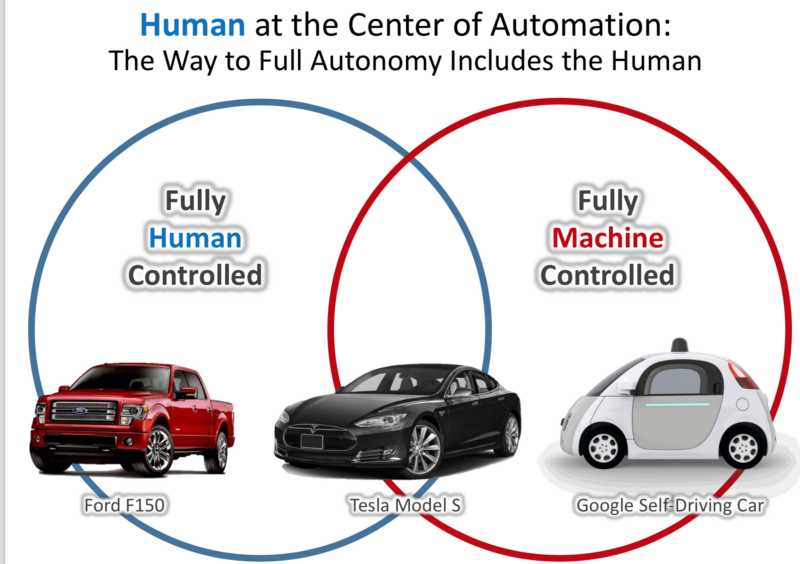
Given these flaws, and the Two Paths to an Autonomous Future (Human Centred Vs Full Autonomy) discussed in Lecture 1:
Is the Human Centred idea a bad idea?


- Humans might tend to ‘over-trust; the System.

MIT-AVT Naturalistic Driving Dataset

Data Collection:
- Two+ One Cameras.
- Camera 1: Capturing HD Video of the Face for Glance Recognition and Estimating Cognitive Load.
- Camera 2: (FishEye) Estimating Body Pose-Hands on Wheel, Activity Recognition.
- Camera 3: Recording scenario outside for Full Scene Segmentation.
The Data collected provides an insight of
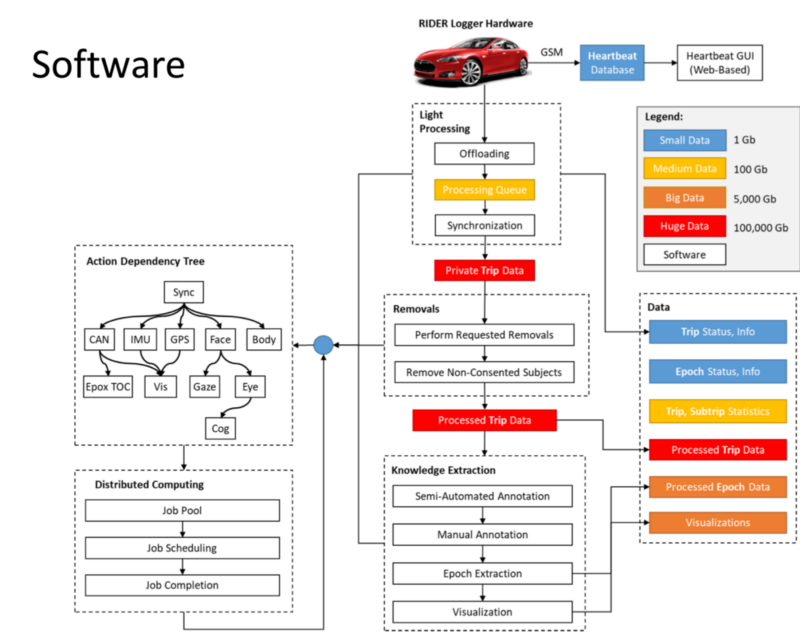
- Human Behaviour.
- Deploying Autonomy.
- Design of Algorithms for Training the Deep Neural Nets for Perception Tasks.
Safety Vs Preference for Autopilot?

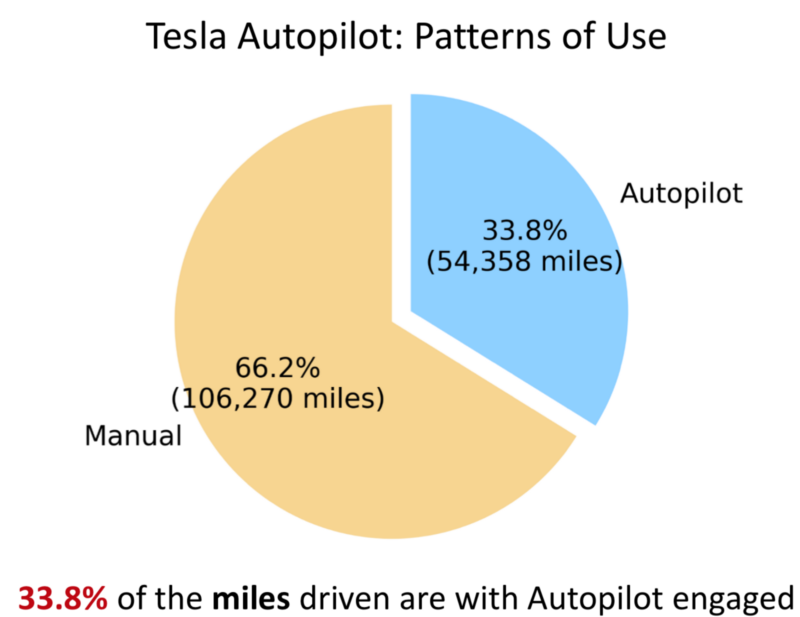
- The Dataset shows that the Physical Engagement remains the same with/without the Autopilot on.
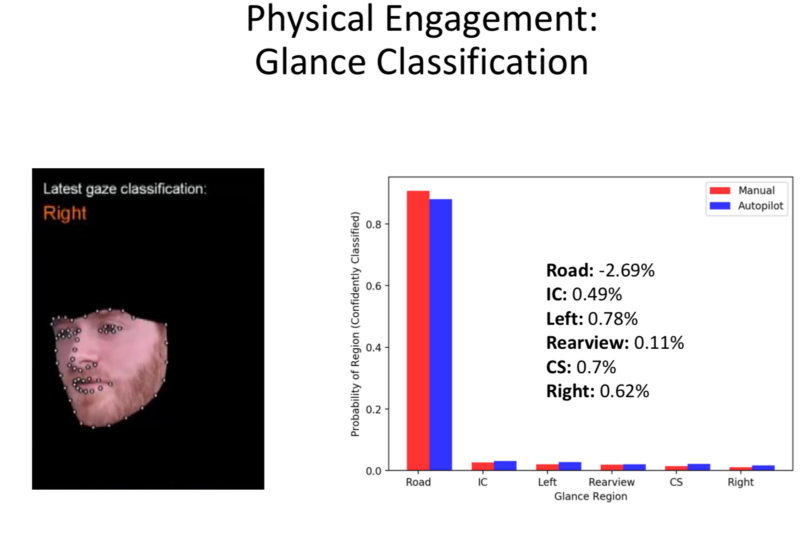
- So, Autopilots allow being physically engaged. But the Systems aren’t over-trusted by the Driver
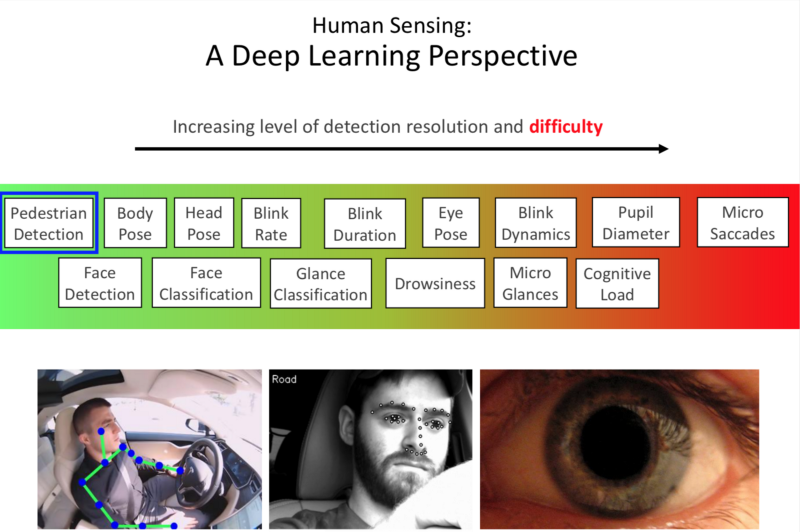
Pedestrian Detection
Challenges:
- Different appearances: Inter class variations.
- Different Articulations.
- Occlusion accessories.
- Pedestrians occluding each other.
Solutions:
The need is to extract features from raw pixels.
Sliding Image:
- Haar Cascade.
- HOG.
- CNN.
More Intelligent netoworks:
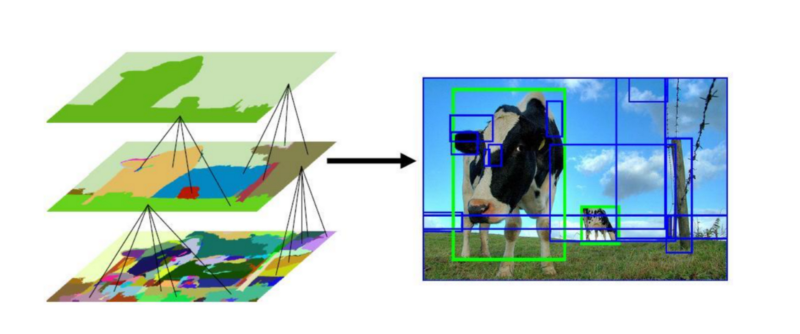
- Fast R-CNN.
- Mask RCNN.
- VoxelNet.
These networks generate the candidates to be considered instead of a sliding window approach, providing a subset to be considered.
- Using a CNN classifier to detect if there is an object of interest present.
- Use Non-Maximum Suppression to remove overlapping bounding boxes.


Data (from different intersections):
- 10 hours recorded every day.
- Aprrox 12,000 Pedestrians Crossing.
- 21M+ samples of feature vector.
- RCNN does a bounding box detection of Pedestrians.
Body Pose Estimation
Includes:

- Finding Joints in the image.
- The landmark points in the image.
Why is it important?
- To determine the alignment of the driver.
- Note: The general airbags are deployed assuming the Driver is facing towards the front.
- With Increased automation, this assumption might fail.
Sequential Detection Approach
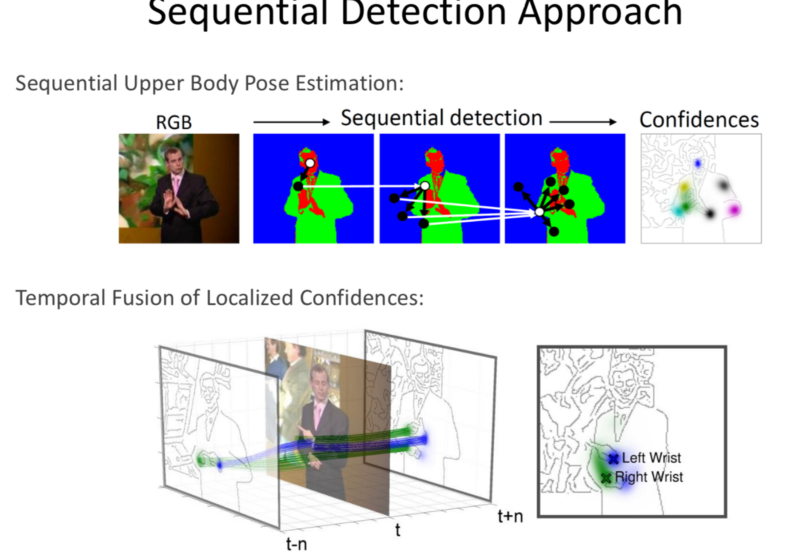
- Detect the Hands and then detecting in steps, the shoulders and so on.
- Traditional Method
DeepPose Holistic View:

- Powerful, successful for Muti-person, multi pose detection.
- Performing a regression of Detecting parts from the complete image individually rather than a sequential detection.
- Later, it stitches the detected joints together.
- Allows detection of varying poses, and joints that aren’t visible.
Cascade of Pose Regressors:
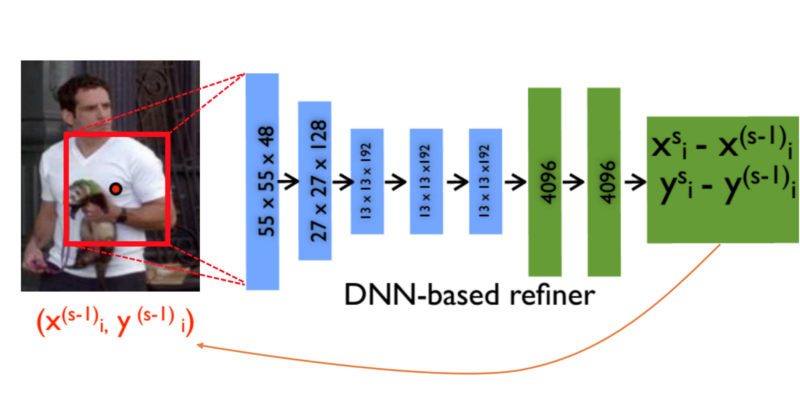
- CNN that take in a raw image and produce a X-Y position of an estimate of each joint.
- Every estimation zooms in and produces repeated finer detection and estimation of joints.
Part Detection:

- We can use this approach to detect parts in a picture with multiple people.
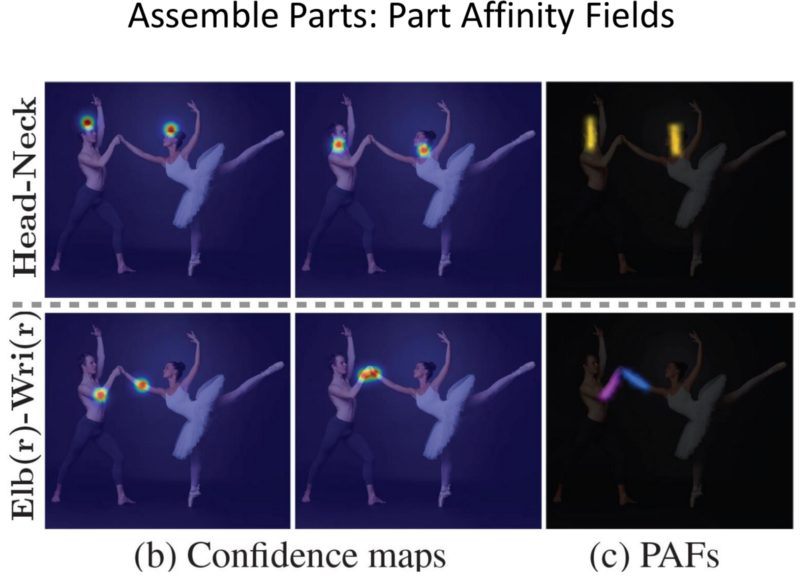
- First, the body parts are detected without doing individual person detection first.
- Next connect them together.
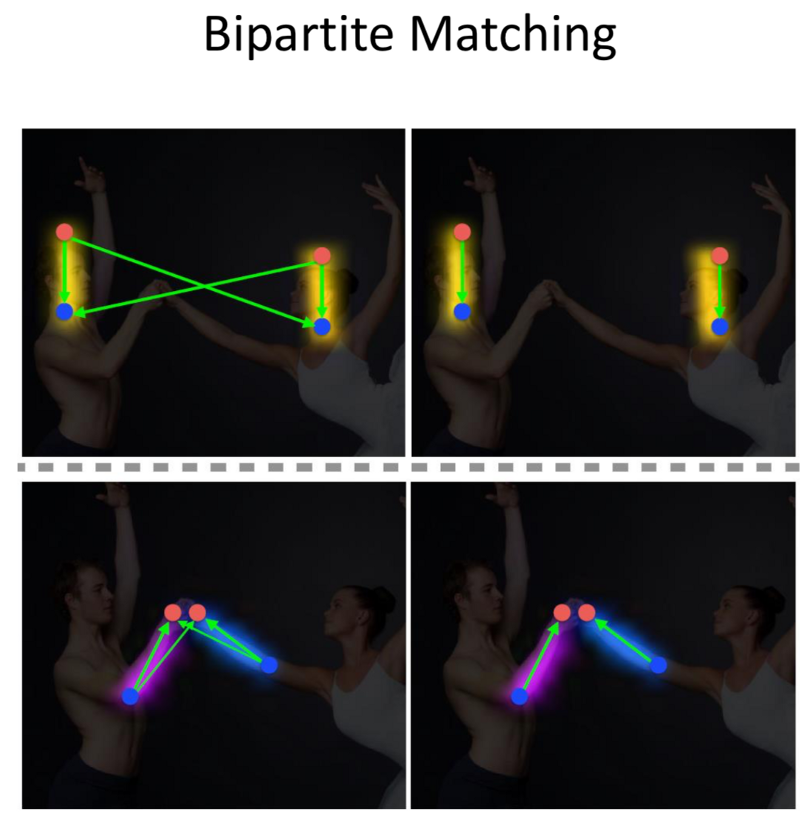
- Through Bi-Partitite matching, stitch the different people together.
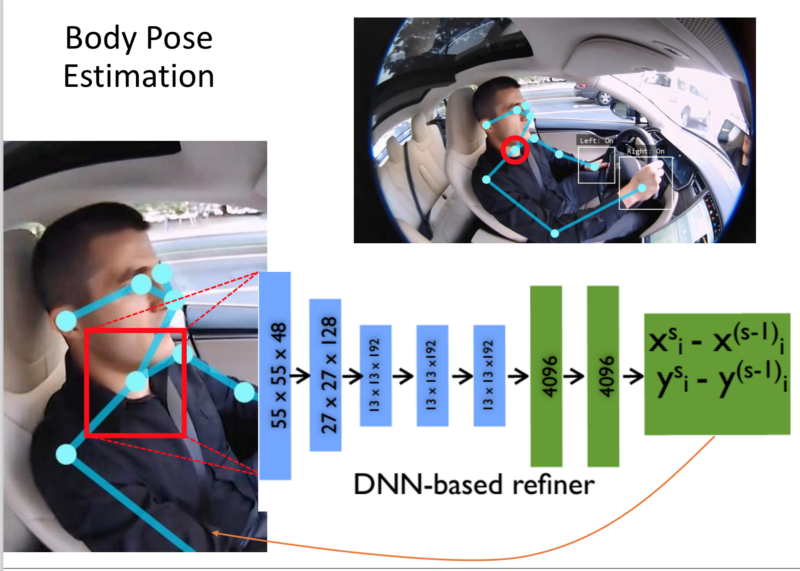
- This is the approach used by MIT, to detect upper body parts.
- Position of Driver Vs Standard Front facing position.
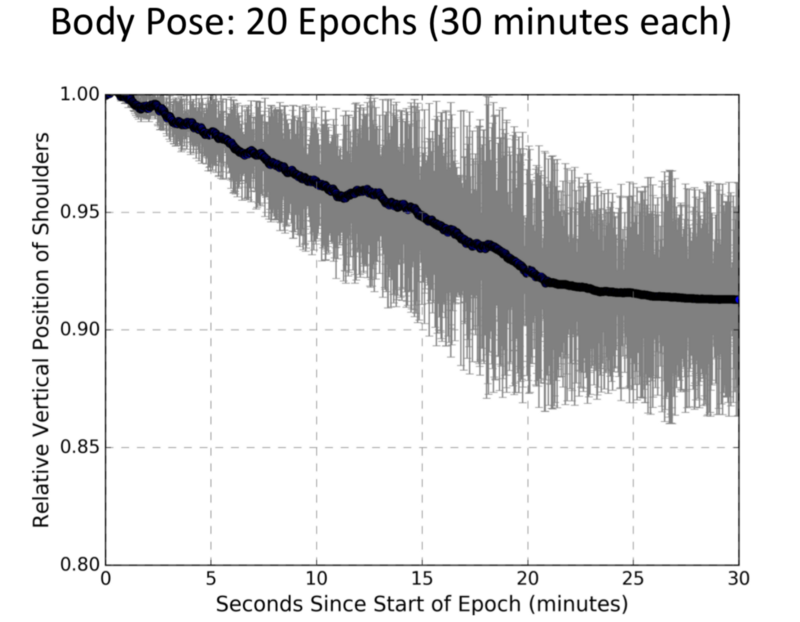
- Plot of Time Vs Position of Neck.
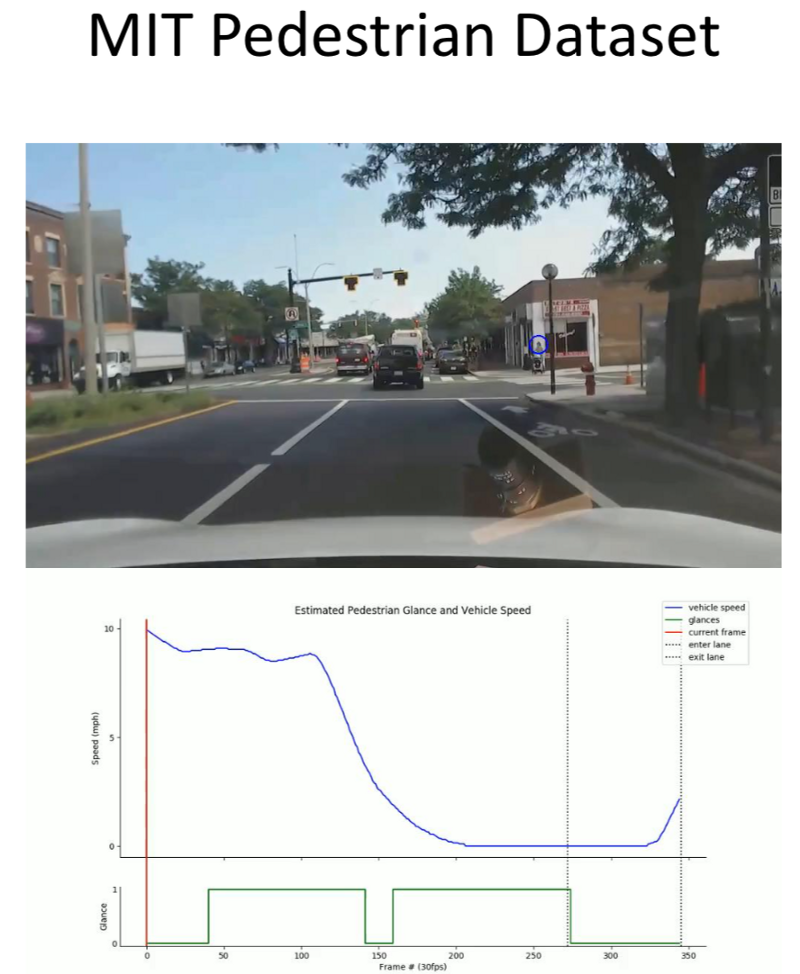
- Body Pose Estimation for Pedestrians.
- This allows detecting the dynamics of ‘non-verbal’ communication that happen when a pedestrian crosses the road and looks at the vehicle.
- Interesting Discovery: Most people look away from the approaching vehicle before crossing the road.
Glance Classification:
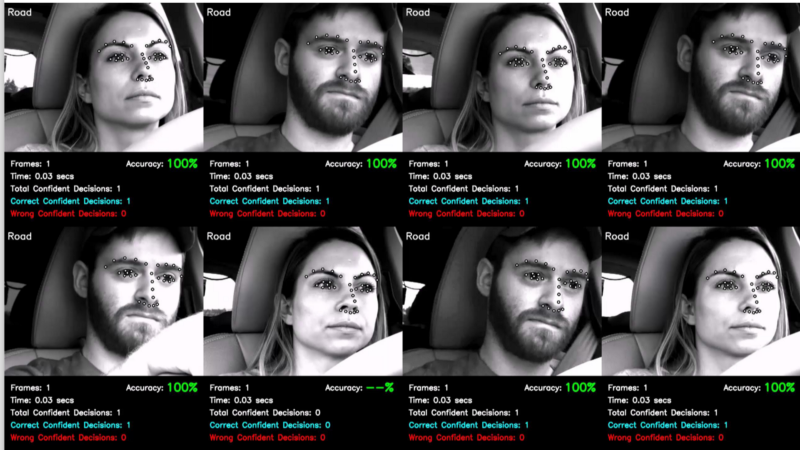
- Determining where the Driver is looking.
- Note: This isn’t the same as gaze detection, where we try to find (x,y,z) pose.
We classify two regions: On-Road/Off-Road.
Or Six Regions:
- On Road
- Off Road
- Left
- Right
- Instrument Panel
- Rear-View Mirror
The classification allows it to be addressed as a ML problem. - The same can be extended to Pedestrian to determine if they are looking at/away from the approaching vehicle.
- Note: The ground data is provided by manual annotation.
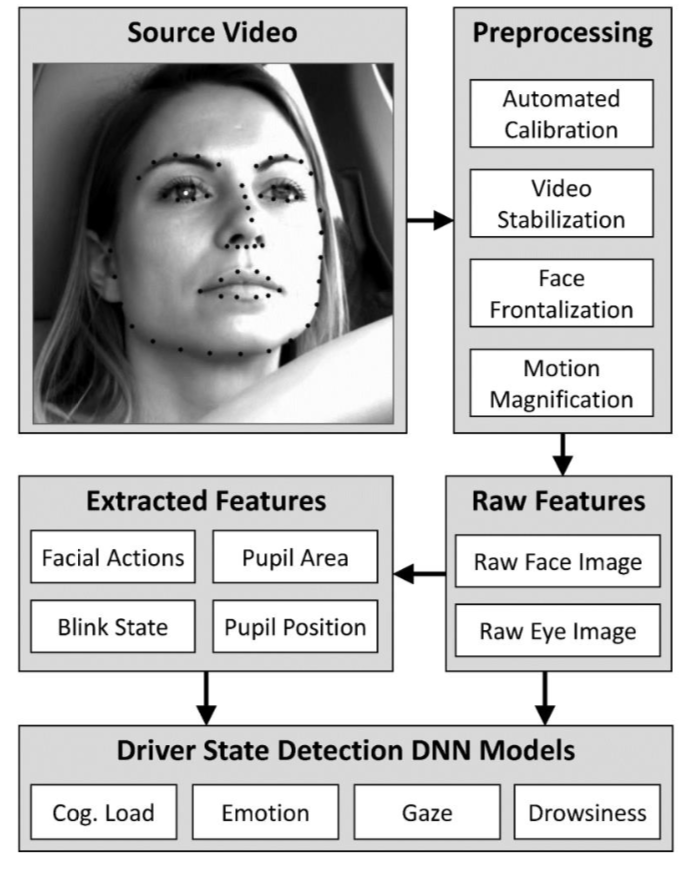
Face Alignment:

- Designing algorithm that are able to detect the individual landmarks of the face and estimating pose of the head.
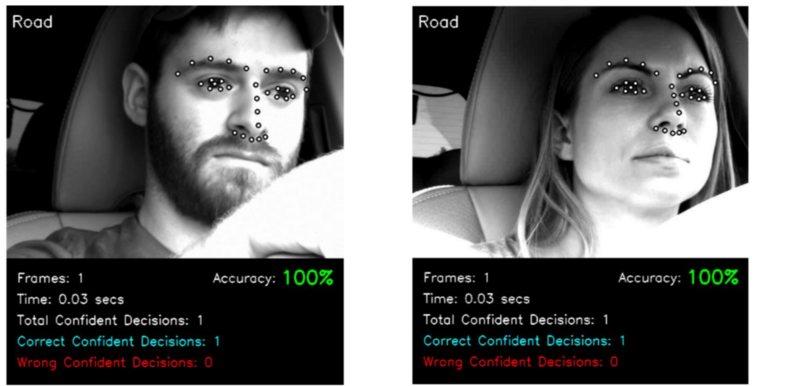
Gaze Classification Pipeline:
- Source Video
- Calibration:
Determining where the sensor is, since its region based. - Video Stabilisation.
- Face Detection.
- Face Alignment.
- Eye/Pupil Detection.
- Head (and eye) pose estimation.
- Classification.
- Decision Pruning.

Annotation Tooling:
Semi-automated: Data that the network is not confident about are manually annotated.
Fundamental Tradeoff:
What is the accuracy we are willing to put up with?
For increase in accuracy, a human manually iterates and annotates thet data.
False Positives:
Can be dealt with by more training data.
Some degree of human annotation fixes some of the problems.
Driver State Detection:

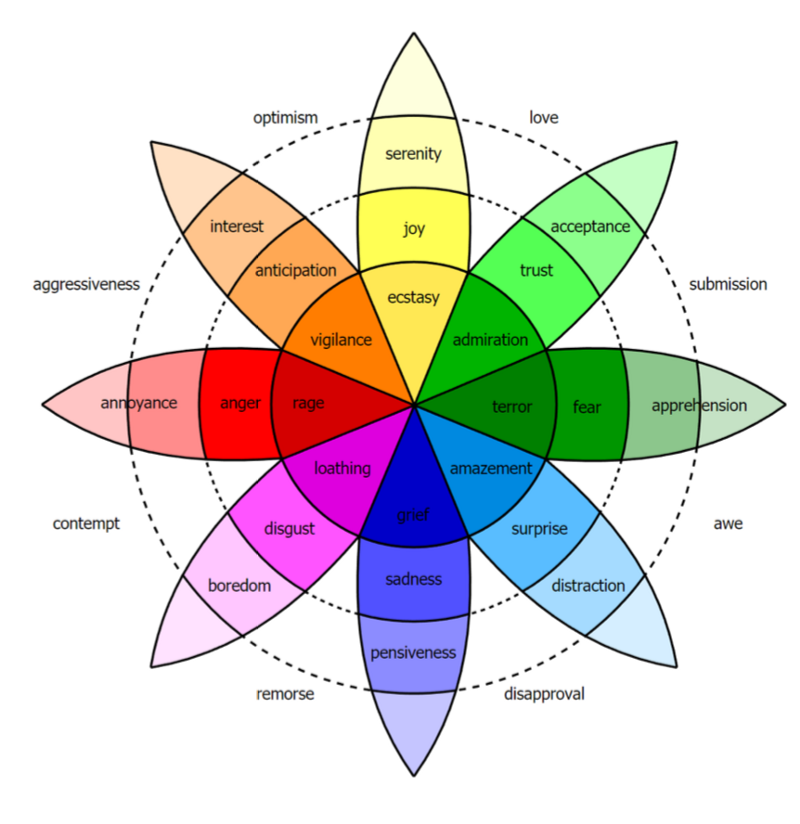
Emotion Detection of the driver.
- Many ways to taxonomize emotion.
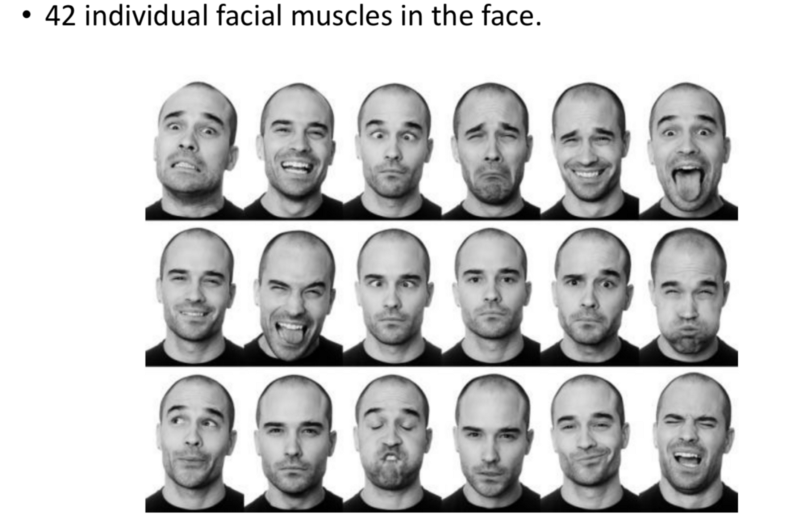
- General Case of detecting emotion.

- Ex: Affectiva SDK.

- These algorithms map our expressions to Emotion.

- Application Specific Emotion Recoginiton:
- Ex: Using Voice based GPS Interaction
- Self Annotated.
- The generic emotion detectors fail here because while driving, ‘smile = frustration’.
- Thus Annotation matters. The data must be labelled to reflect these situations.
Cognitive Load:
Degree to which a person is mentally busy.
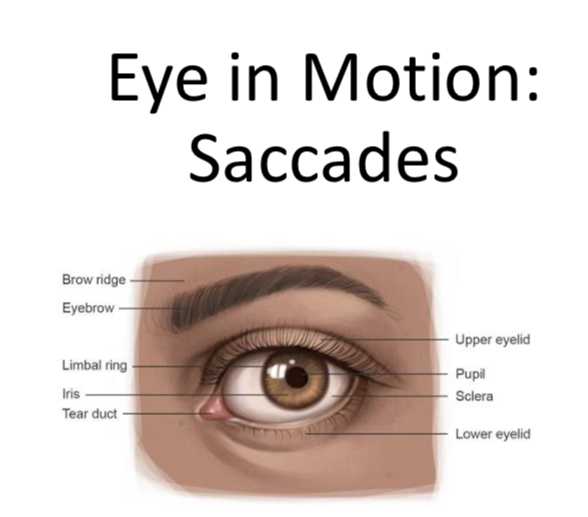
- Eyes expand and contract based on Cognitive load, movements reflect deep thought too.
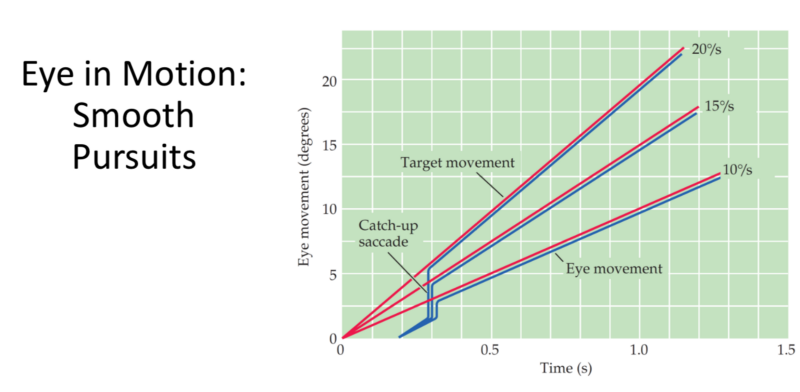
- Cognitive load can be detected with blink dynamics, eye movement and pupil dilation.
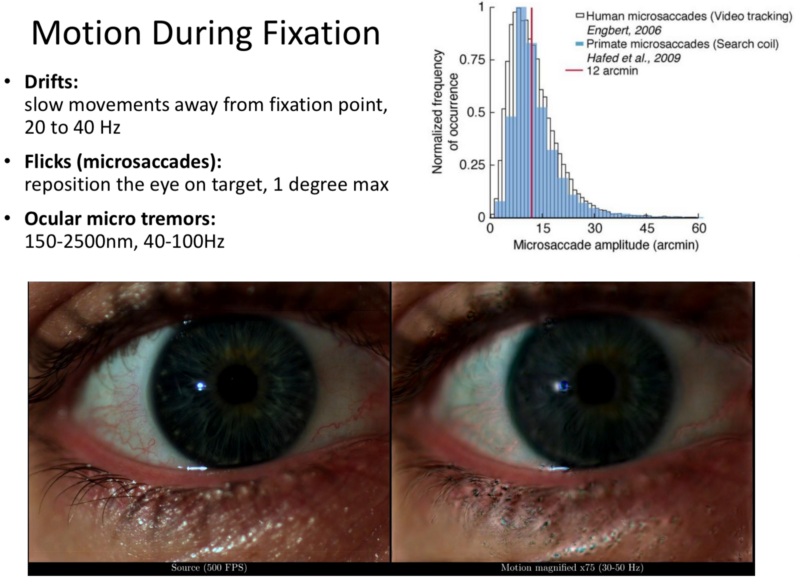
- However, in real world lighting leaves out pupil dilation.
- Blink dynamincs, eye movement are utilised.
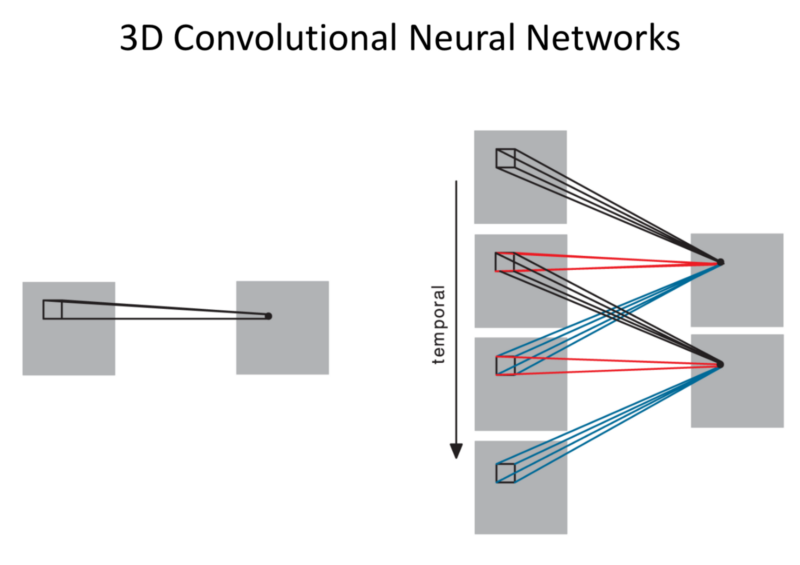
- 3D convolutional NN:
- A sequence of images is inputed, we use 3D convolutions.
- Convolve across multiple images/channels.
- Allow learning dynamics through time. - Real World Data:
N-back tasks to estimate cognitive load.
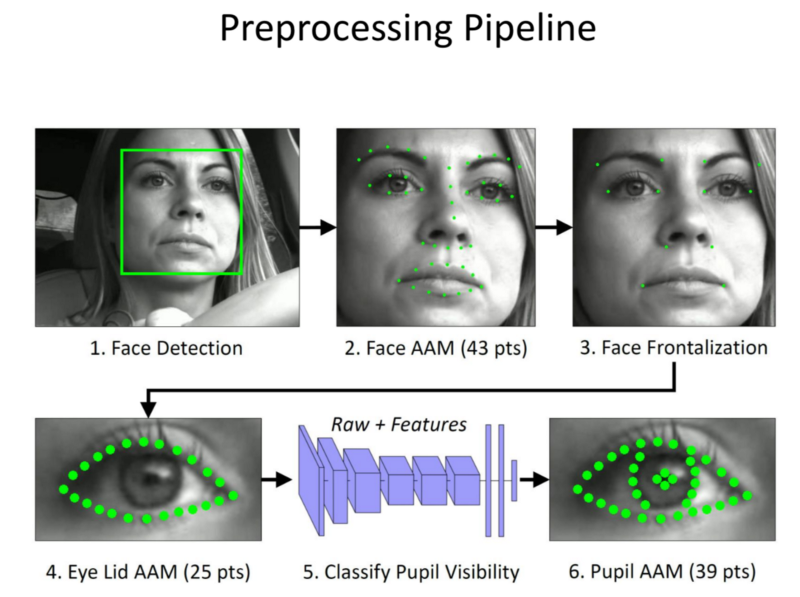
- We detect face, extract eyes and feed these into a CNN.
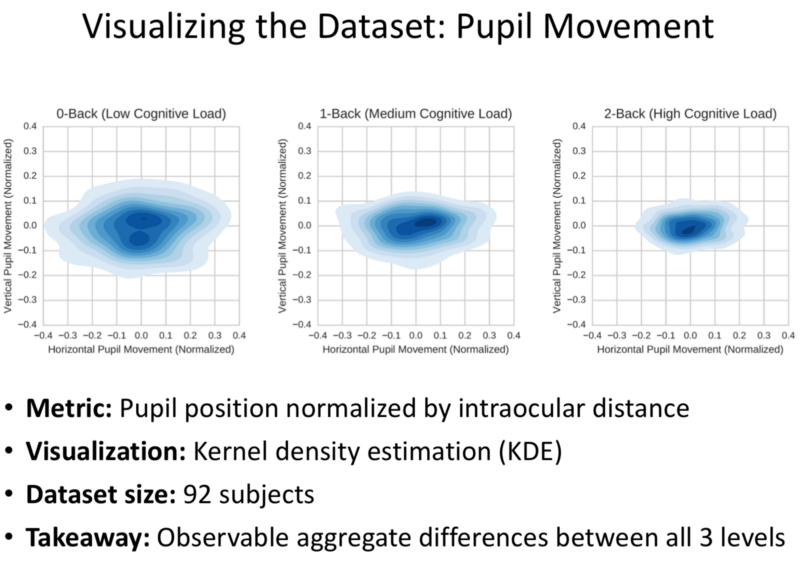
- Plot of Eye Movement Vs Cognitive Load.
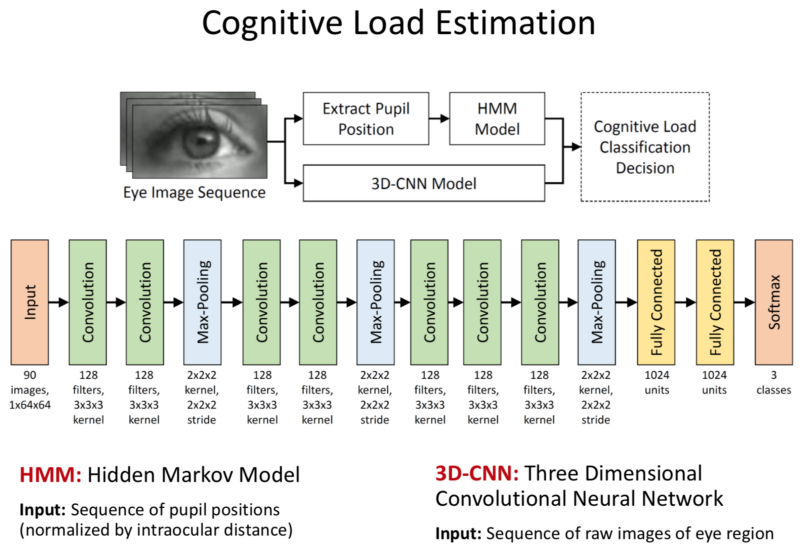

- Standard 3D CNN Architecture.
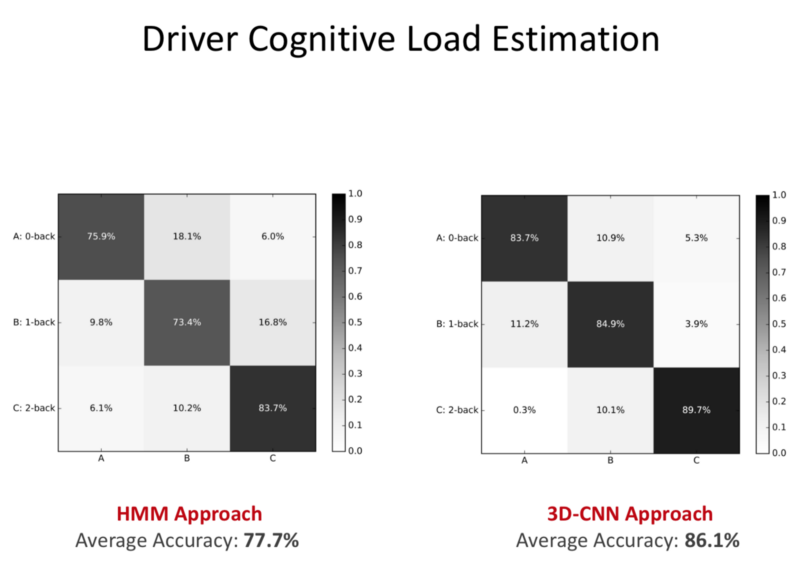
- Accuracy on real world data.

Human Centred Vision for Autonomous Vehicles:
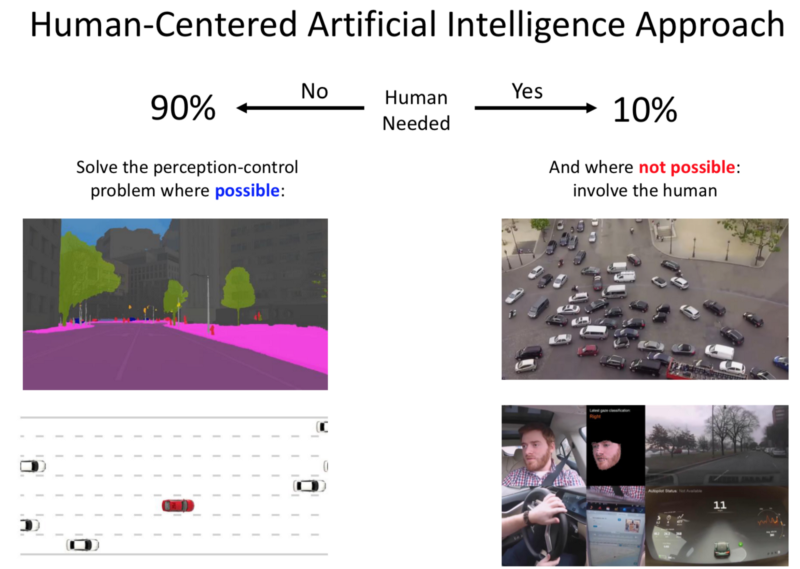
- Even though we are researching on perception, utilising sensors for localisation and path planning. We are still distant from solving this (Argument: 20+ years).
So, Human has to be involved.
- Thus, the ‘Robot’ needs to understand the ‘Human’s activity’ and the Human-Robot interaction needs to be refined.

- Path to Mass Scale Automation.
(No more steering wheels) - Human Centred Autonomy:
- A SDC is a personal robot rather than a Perception Control System.
- The ‘Transfer of Control’ involves a ‘Personal’ Connection with the machine.
- SDCs will be wide reaching.

- Teaser: MIT SDC will debut on the public streets (Public Testing) in March, 2018.
- What Next?
- DeepTraffic
- DeepCrash
- SegFuse
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science
