
You can find me on Twitter @bhutanisanyam1
You can find the Markdown File Here
You can find the Lecture 1 Notes here
Lecture 2 Notes can be found here
Lecture 3 Notes can be found here
Lecture 5 Notes can be found here
These are the Lecture 4 notes for the MIT 6.S094: Deep Learning for Self-Driving Cars Course (2018), Taught by Lex Fridman.
All Images are from the Lecture Slides.

Computer Vision: Teaching Computers to See.
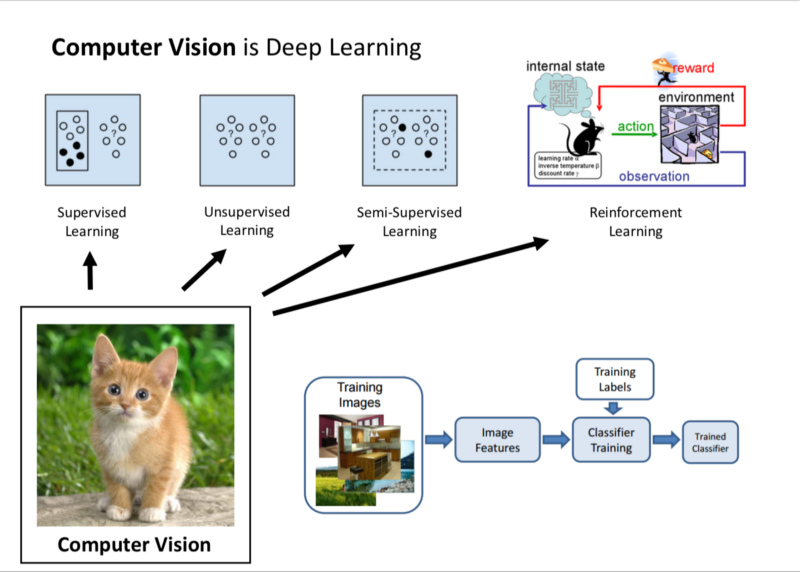
Computer Vision, as of Today is Deep Learning. Majority of the successes of our understanding of images, utilise Neural Networks.
- Supervised Learning: Annotated data is provided by Humans. NN parses through the data maps from the raw sensory data to image categories and for a sanity check, it should perform well on a test set.

Raw Sensory data: For the machine, images are in the form of numbers.
The images in the form of 1 channel or 3 channel numerical arrays, are taken as input by the NN, the output is produced by regressing or by classifying the image into various categories.

We must be careful about our assumptions for what is easy and hard with Perception.
Human Vision Vs Computer Vision.
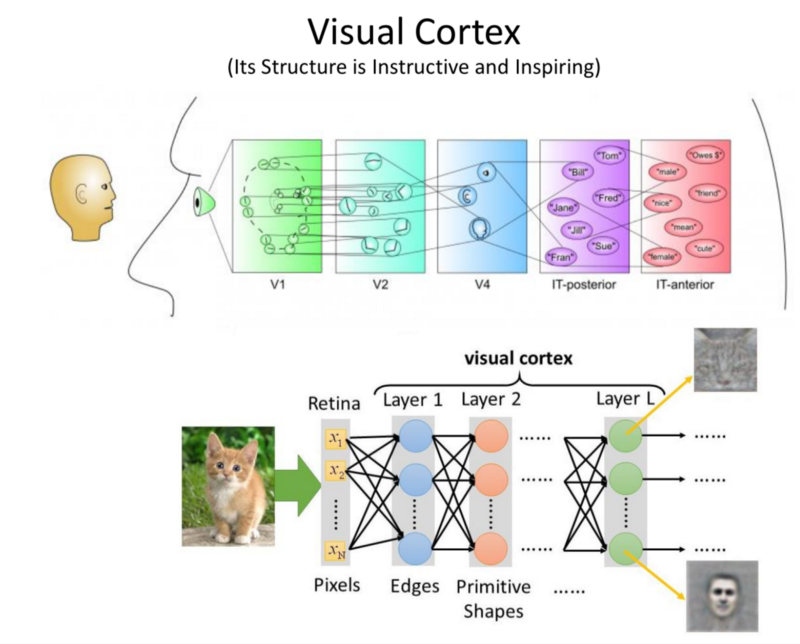
- Structure of the Visual Cortex is in layers. As information is passed from our eyes to the brain, higher and higher order representation are formed. This is the inspiration behind Deep NN for images. Higher and higher representations are formed through the layers.
The early layers, taking in the raw pixels, finding edges. Further finding more abstract features by connecting these edges. Finally, finding higher order semantic meaning. - Deep Learning is hard for Computer Vision:

- Illumination variability is one of the biggest challenges in driving.

- Pose Variablity: NN are not good with representing pose. Objects in 2D plane of colour and texture look very different when the objects are rotated.

- Inter-class variablity: For Classification problems, there is a lot of variability inside the classes and very little between the classes.

- Occlusion: When part of the object is occluded by another object and we are tasked with identifying the object that is occluded.

- Philosophical Ambiguity: Image classfication !=Understanding.
- Unsupervised Learning
- Reinforcement Learning.
Image classification Pipeline:
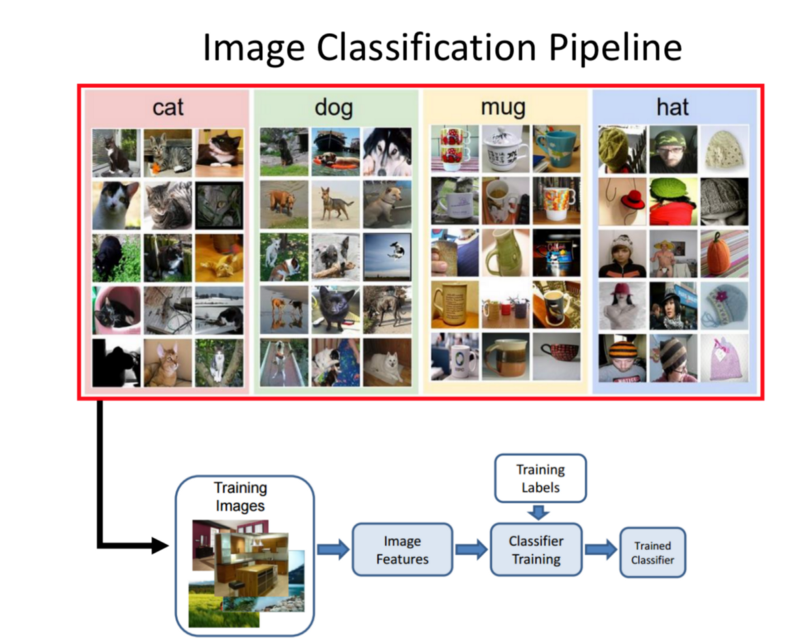
There is a bin with different categories inside each class. Those bins have a lot of examples of each. Task: Bin a new image into one of these classes.
Famous Datasets:

- MNIST
- ImageNet

- CIFAR-10
One of the Simplest ones, containing 10 categories is commonly used to explore CNNs.
Trivial Example:

- Comparing images by subtracting the pixel intensity matrices and then sum up the differences of every element. If the sum is high, the images are different.
If we use this methodology, we can get 35% accuracy using L2 diff, 38% with L1 diff these are better than the random accuracy of10%.
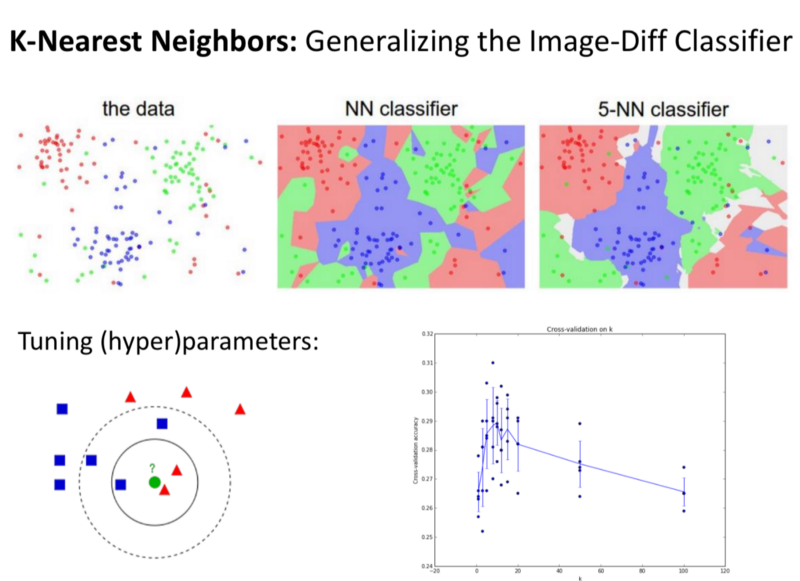
- K-Nearest Neighbours:
Instead of finding the 1 image that is the closest to our dataset, we try to find k-closest images and bin them into k-classes. We vary the k from 1–5 and see how that changes the problems.
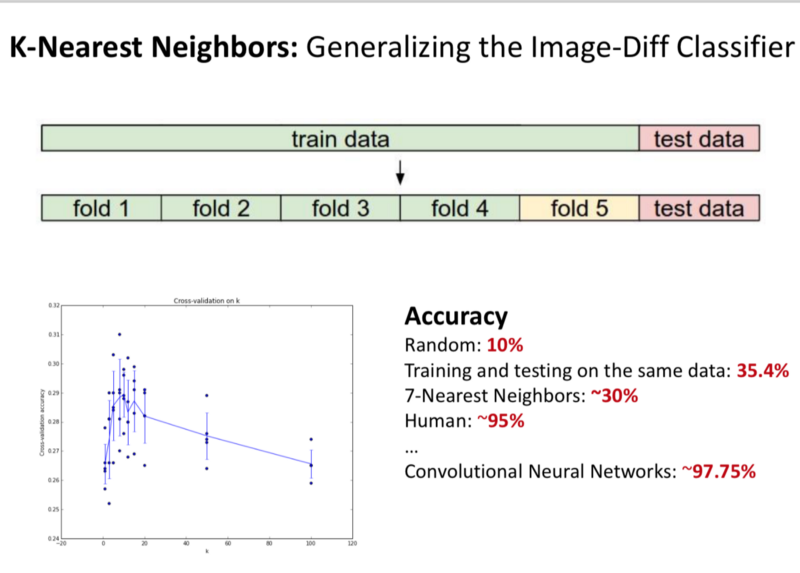
- With k=7, we achieve 30% accuracy.
Human level accuracy is 95%.
With CNNs, we get 97.75% accuracy.
Working of Neural Networks:
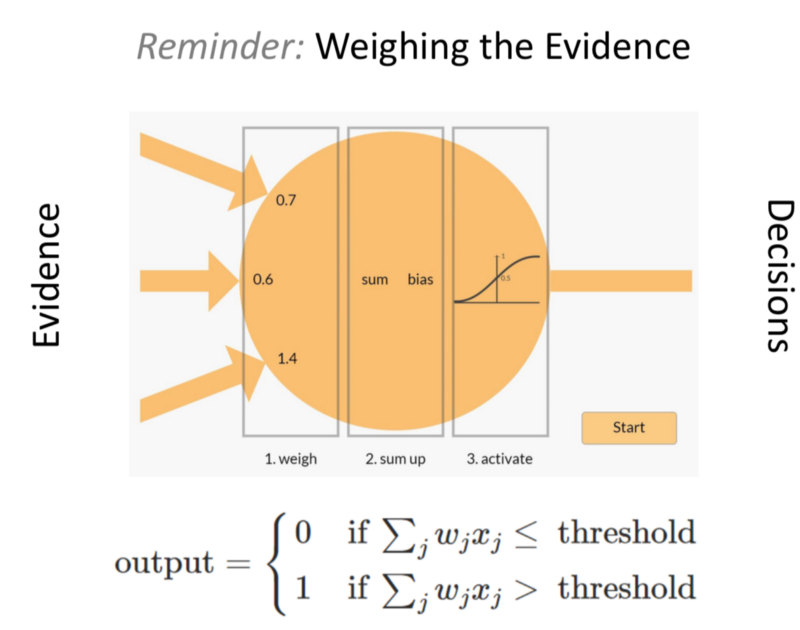
- Each input signal is weighed, biased and added.
- These are then inputted to a non-linear activation function.
- Put together in more and more layers, these form a Deep NN.
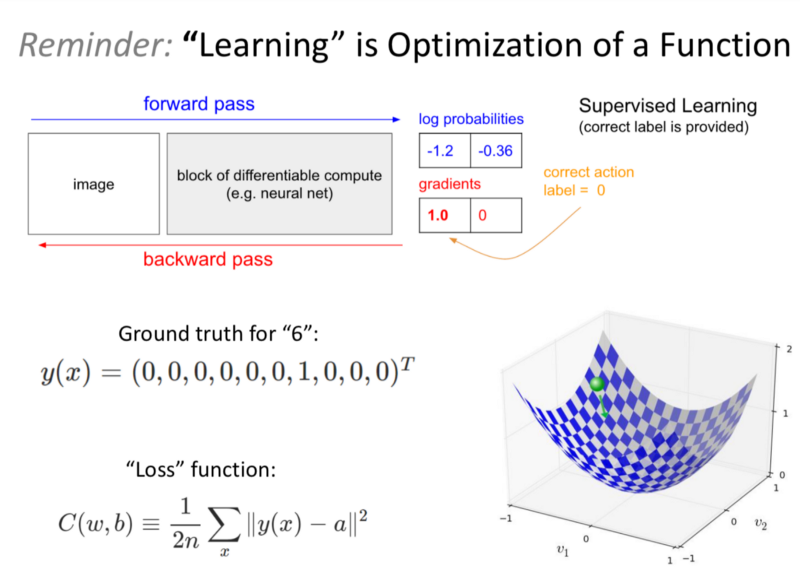
- The NN Trains by making a forward pass, evaluating how close are examples are to the ground truth and then punishing the weights that resulted in incorrect decisions and rewarding the weights that had resulted in the correct decisions.
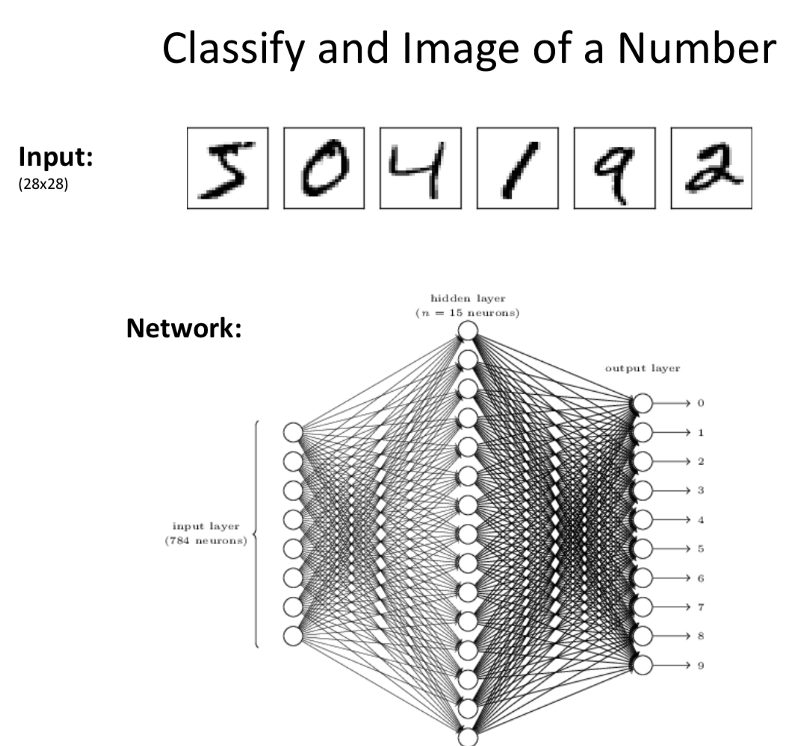
- Ex: MNIST-For the Case of 10 cases, the outputs is 10 different values.
- Each Neuron gets excited based on the class it represents.
- The output is assigned to the class that shows the highest value of activation.
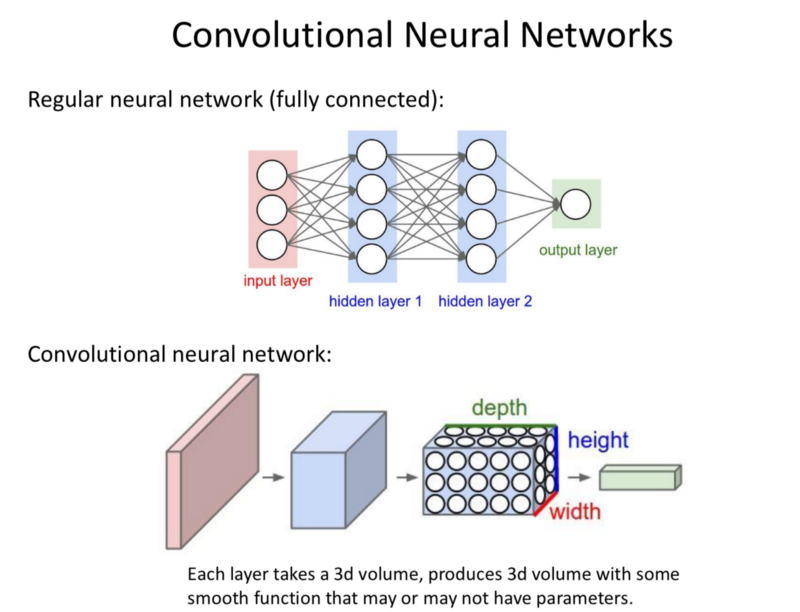
When the NN is tasked to learning a complex task with large data and large number of objects, CNNs work efficiently.
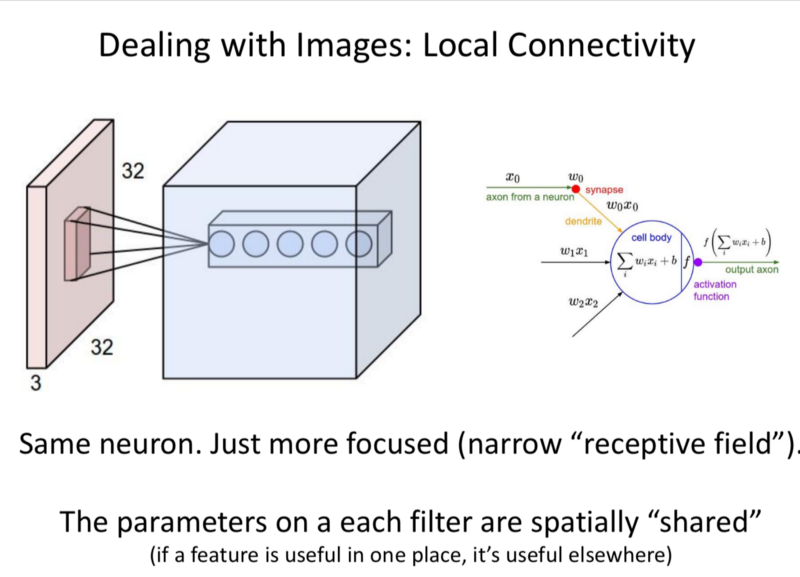
‘Trick-Spatial Invarince’:
An Object in the top left corner is the same as the object in the bottom right corner of an image. So we learn the same features across the image.
Convolution operation: Instead of the Fully connected layers; Here a 3rd dimension of depth is present. So the block take 3 input volumes and produce 3D output volumes
They take a slice of the image, ‘a window’ and slide it through the image. They apply the same weights to slice/window of an image to generate outputs. We can make many such filters.
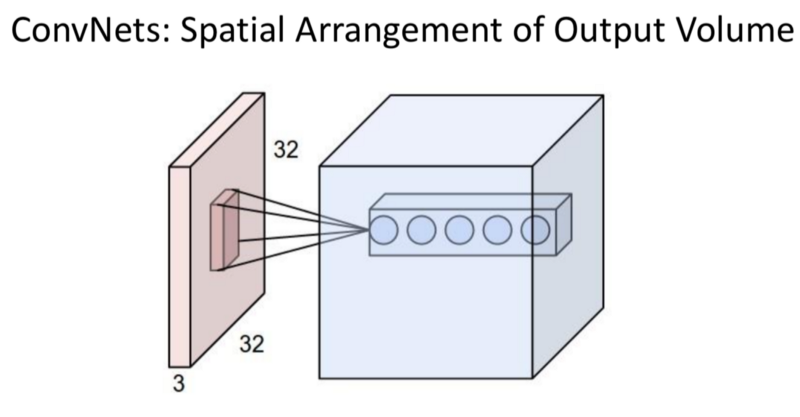
Parameters on each of these filters are shared. (If a feature is useful in one place, it’s useful everywhere) This allows parameter reduction significantly. The re-use of spatial features.
- The Depth: The number of filters.
- Stride: Pixels skipped when applying the filter
- Padding: Adding 0 values on the borders to the input for the Convolutional layer.
Example:
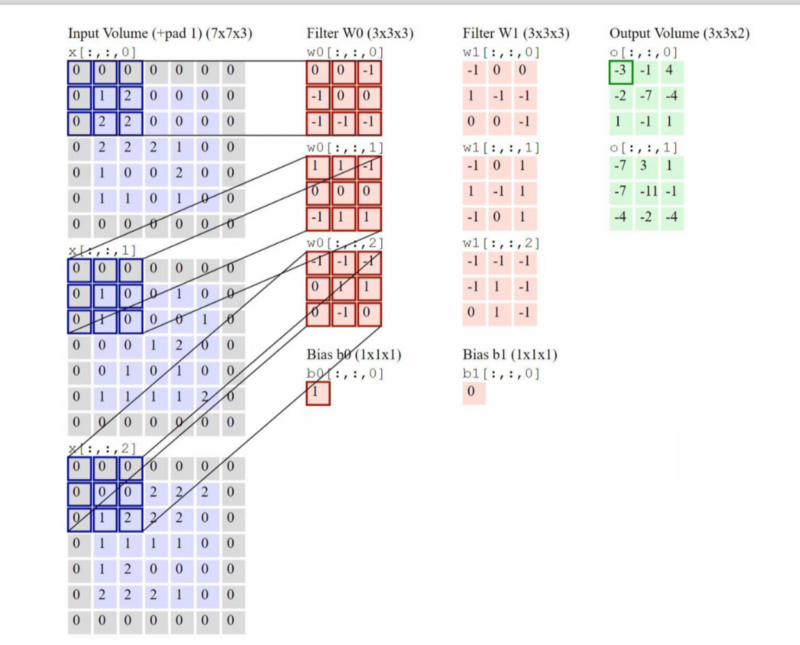
- Left Column: 3 Input Channel.
- Filter W0: 2 channels of filter, each of size 3x3.
- The 3x3 filters are to be ‘learned’
- These are slided across the image to produce the output.
- The operations are applied to produce the output.
Convolution

- The image is inputted.
- We perform the identity filter to generate the Convolved image.
- We perform different other filters to generate the Edges.
- We can detect any kind of pattern and produce the outputs.
- Depending on the filters, you’d have equal number of outputs, each showing where the patterns were found.
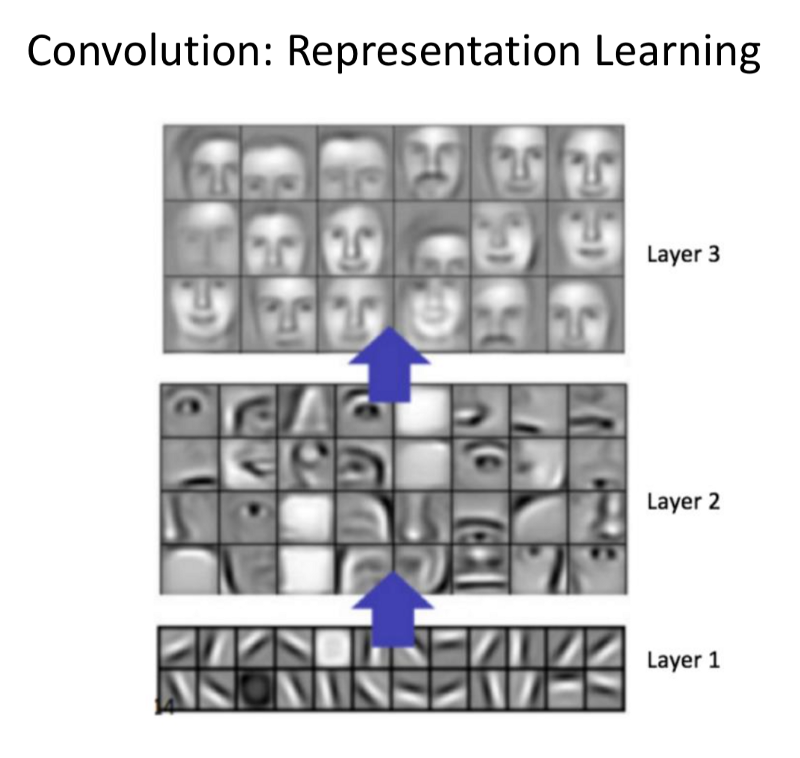
- Task: Learn the useful patterns required for the classification task.
- The filters have higher and higher order for representation.
- Starting with edges, finally to the high semantic meaning spanning the images.
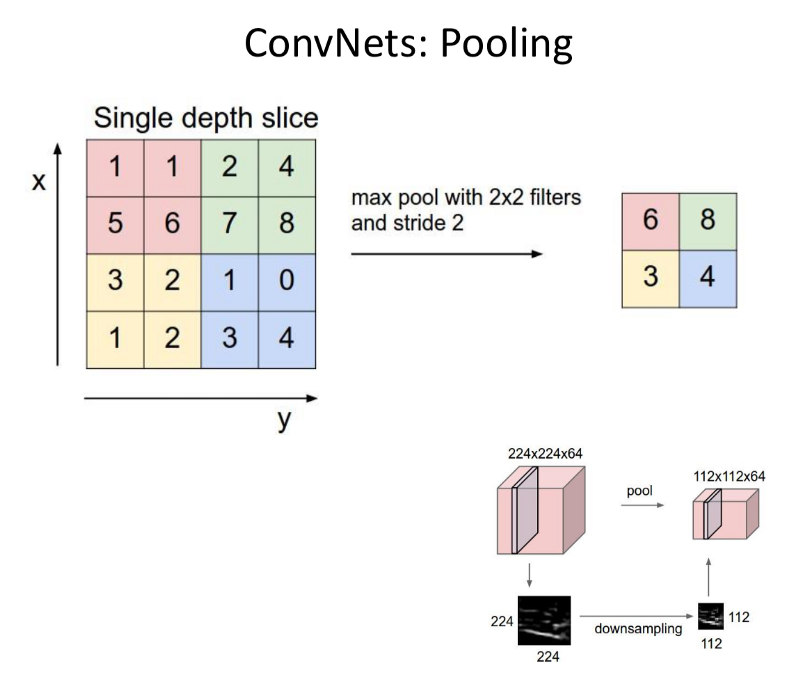
- Spanning Images: Pooling.
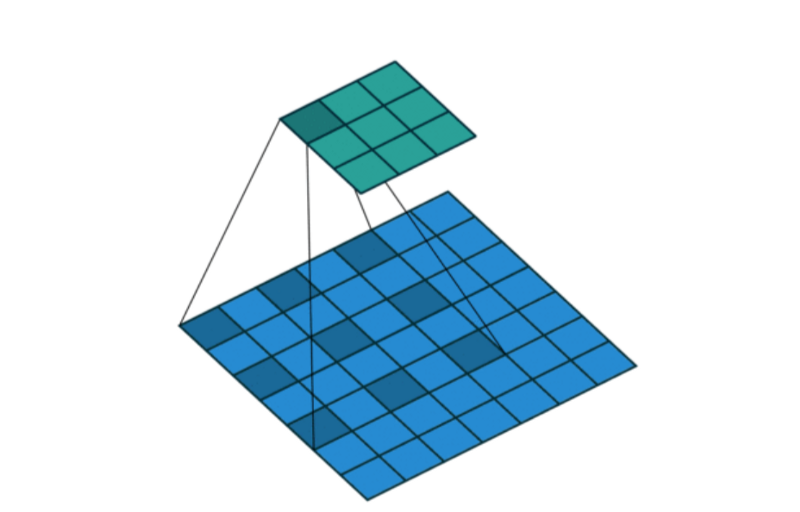
Taking the output of a convolutional operation and reducing the resolution of that by condensing the information, for example considering the max values in Max-Pooling. - Note: The ‘reduction in spatial resolution’ has detrimental effects when it comes to scene segmentation, but is better at finding higher order representation in images for classification.
- Many such Convolutional Layers form a CNN.
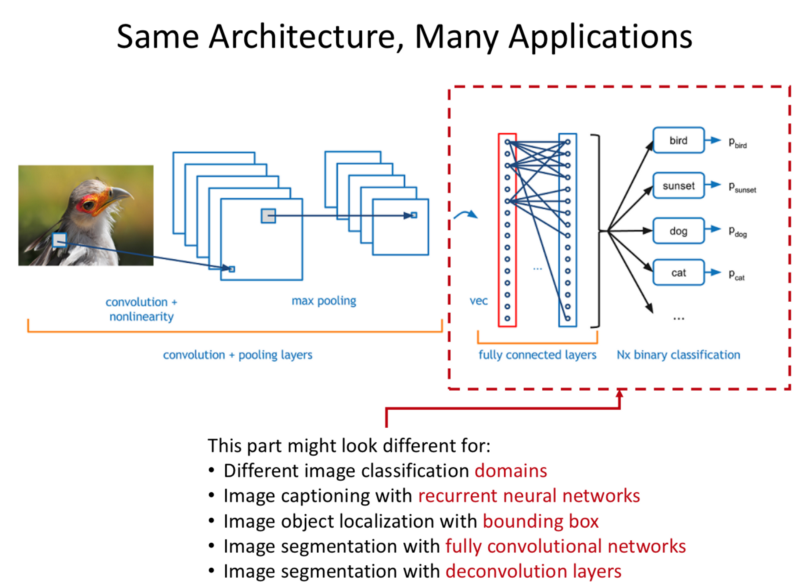
- The Fully Connected layers allow us to apply this to particular domains.
ImageNet Case Study
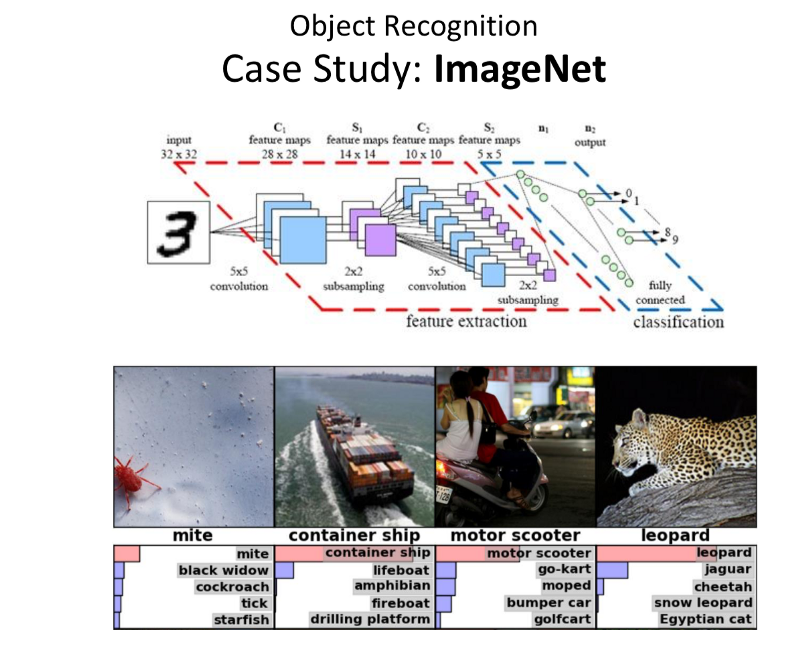
- Task: Classification of one of the largest dataset of images.
14M+ Images
21k+ Categories
With Many Sub-Classes - These provide a good challenge to the check the Pose, Intra Class Variability, Illumination.
- Networks:
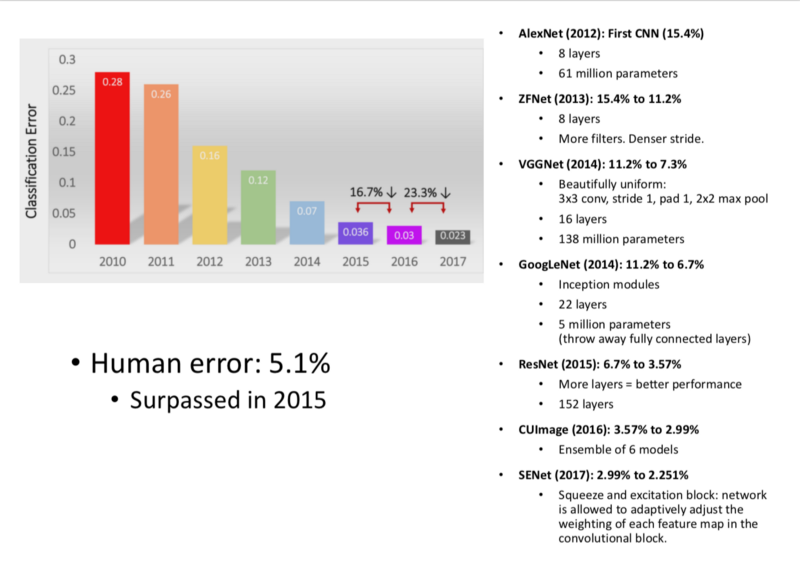
- AlexNet 2012: First Significant Improvement.
- ZFNet 2013
- VGGNet 2014
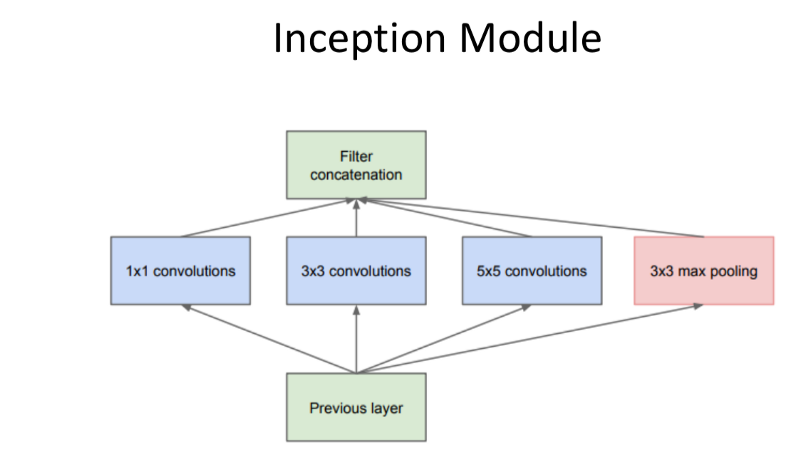
- GoogLeNet 2014
Inception Modules were introduced.
Idea: It used the idea that different sized convolutions provide different value for the network, doing different convolutions and concatenating.
Smaller convolutions: Features that are very Local/High res in texture.
Larger Convolutions: Higher/More Abstract Features.
Result: Fewer Parameters and Better Performance.
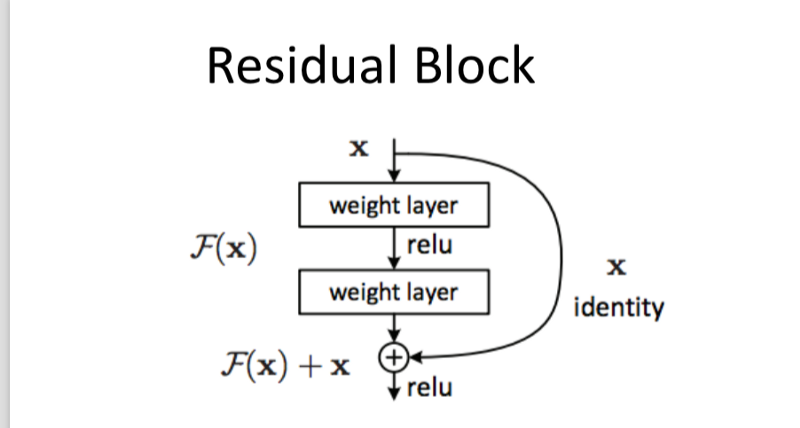
- ResNet 2015
Inspiration: (Doesn’t always hold) Network depth increases representation power.
‘Residual blocks’ allow creating much ‘Deeper’ Networks.
Residual Block:
- Repeat a Simple Network Block, similar to RNNs.
- Pass input along without transformation, along with the ability to learn the weights.
- Every layer takes in the input of previous layer and the raw, untransformed data to learn something new. - CUImage 2016
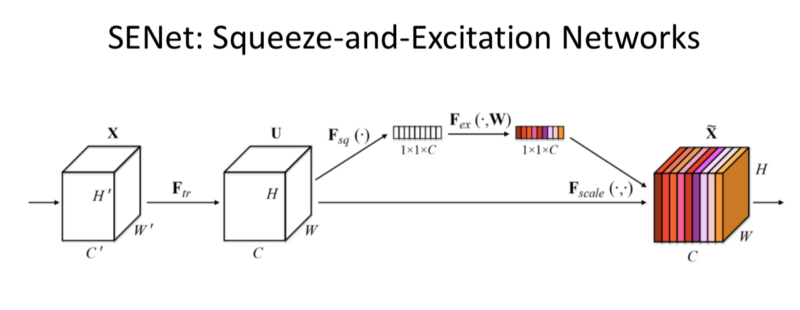
- SENet 2017
Squeeze and Excitation Network:
- Added a parameter to each channel of a convolutional block so that the network can adaptively adjust the weighting of each channel based on each feature map/input to the network.
- Trick: Allow the Network to learn the weighting on each individual channels.
- Note: This is applicable to any architecture. Since, it simply parametrises which filter to pick based on the content.
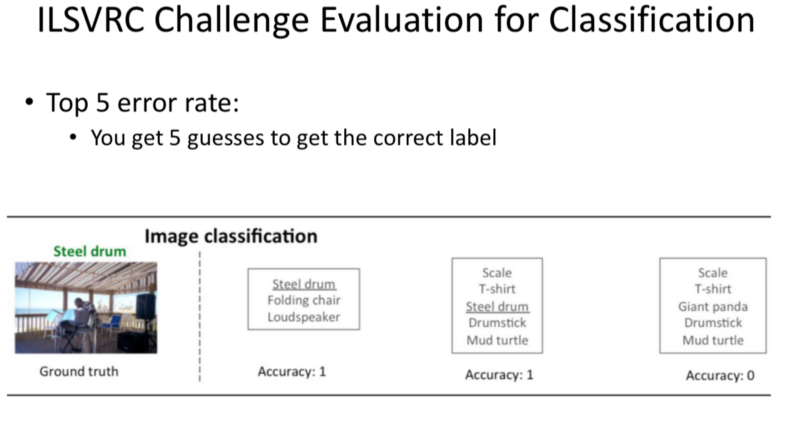
- ILSVRC Challenge Evaluation for Classification
Top 5 guesses.
Human Error is 5.1%
Surpassed in 2015.
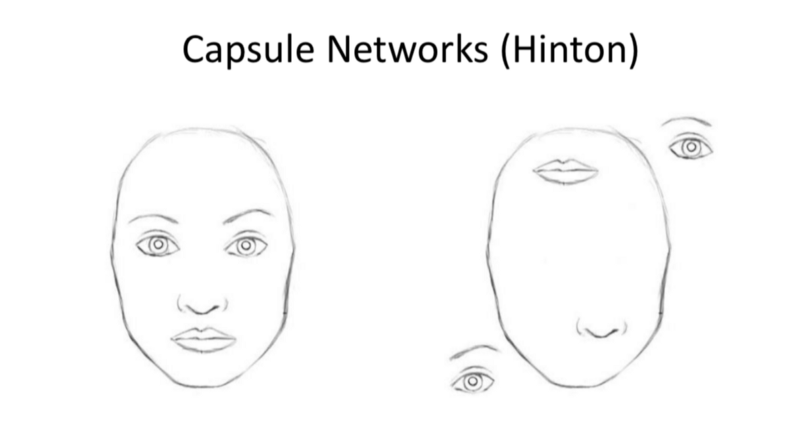
- Capsule Networks:
- Inspiration: Consider what assumptions are made by the network and what information is thrown away.
- CNNs, due to their spatial invariance-throw away the hierarchy between simple and complex objects.
- Future challenge: Design NN that work with Rotational.
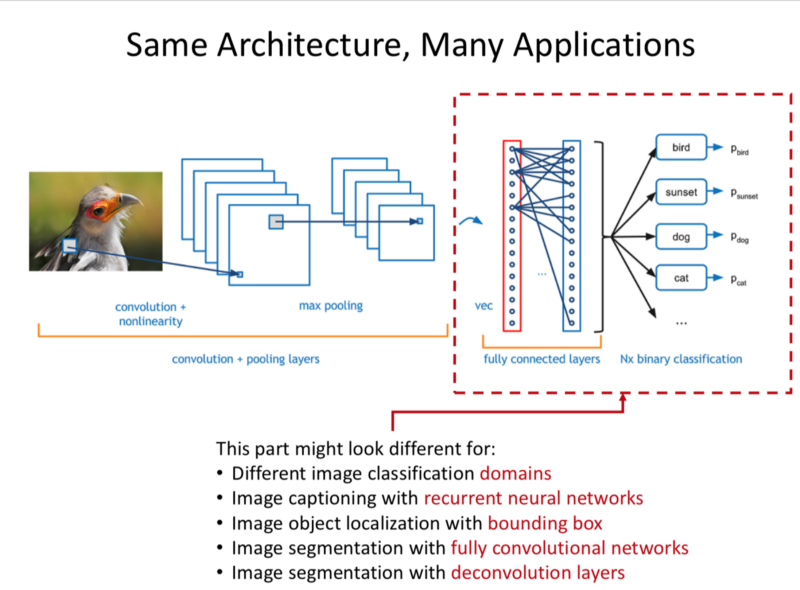
- We take a CNN, change the last layers to apply them.
Object Detection
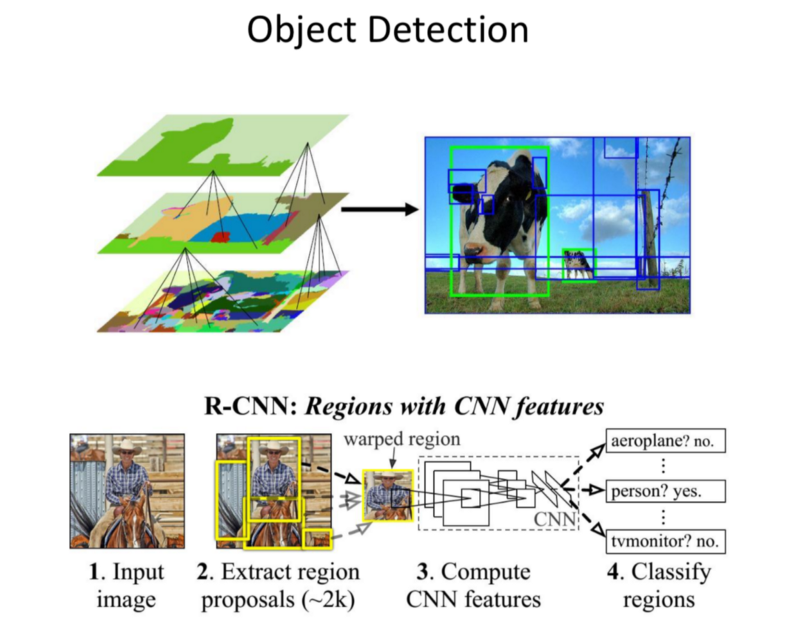
Note: CNN produce a pixel level heat map of activations based on convolutions
Scene understanding

- Goal: Classify every single pixel in the 2D projection, for the real 3D world.
- Challenge: Marking boundaries at pixel level.
- Use-Cases:
- Precise boundaries of Object Matters in Medical, Driving.
- In Driving, to mark exact boundaries of environment. ‘Fuse’ this with data from sensors. So fusing the semantic knowledge with 3D location in real world.
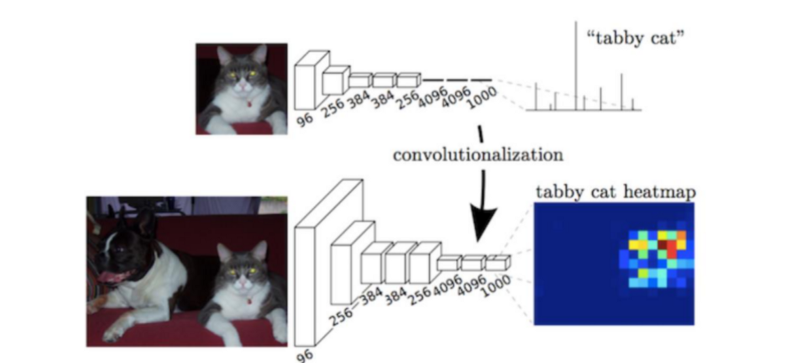
- FCN 2014:
- Repurpose the ImageNet pretrained Nets
- Replaced the Fully connected layers with decoders that upsampled the image to produce a heat map.
- Connections are skipped to improve the coarseness of upsampling.
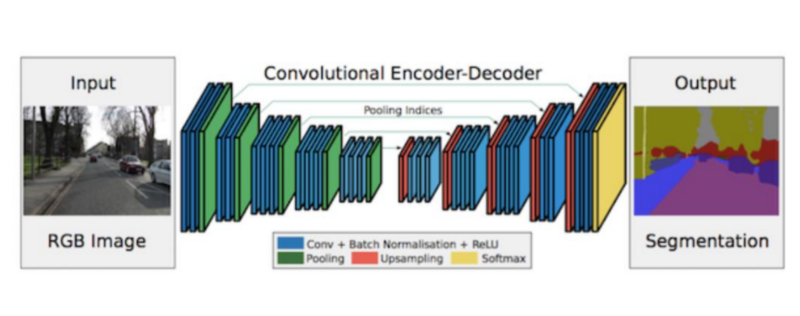
- SegNet 2015:
- Applied this to Driving Context.
- Dilated Convoltions 2015:
- Convolution operation as pooling operation reduces the resolution significantly.
- ‘Gridding’ maintains the local high-res textures while still capturing the spatial windows necessary.
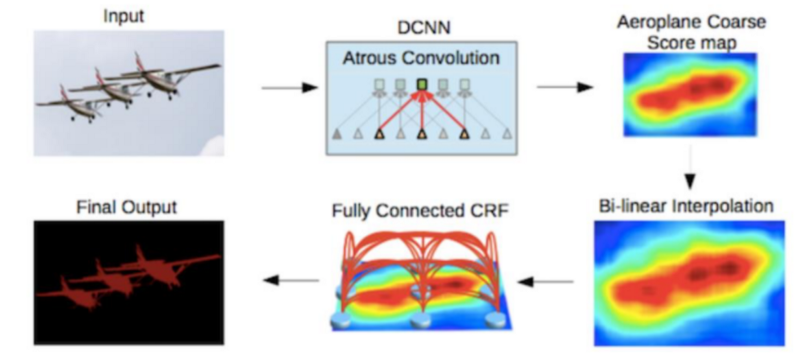
- DeepLab v1,v2 2016:
- Added Conditional Random Fields (CRFs): Post processing to smooth the segmentation by looking at the underlying image intensities.
Key Aspects of Segmentation
- Fully Convolutional Network.
- Conditional Random Forests.
- Dilated Convolutions.
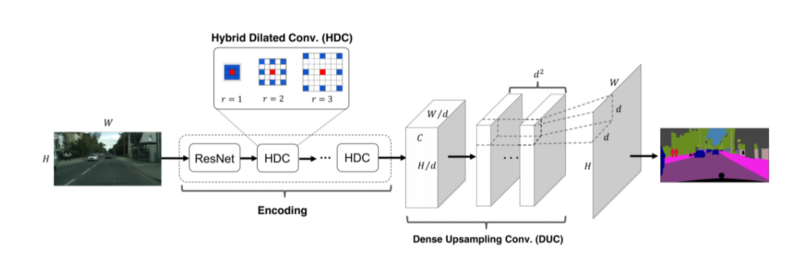
ResNet-DUC 2017:
- Dense upsampling Convolution, instead of bilinear upsampling to learn the upscaling features.
- Hybrid Dilated Convoltion:
Convolution is spread apart from Input to output. - Trick: Parametrisation of The upscaling features.
FlowNet
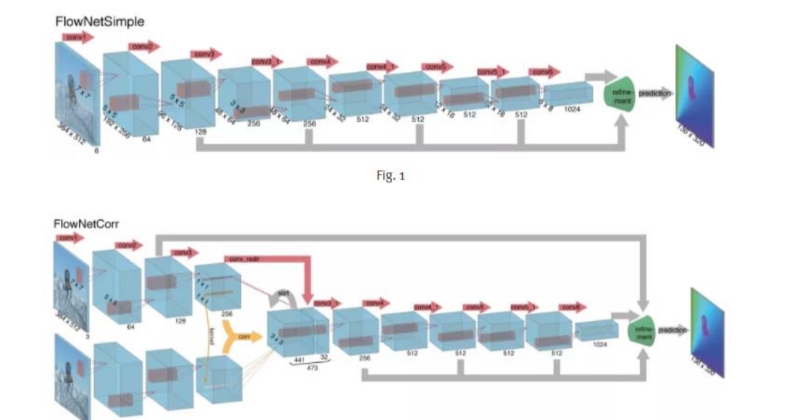
The methods discussed here, disregard the temporal dynamics, which is relevant in the case of Robotics.
- Flow is helpful in approximating how each pixel in the input image moved wrt output image.
- The Optical flow produces a direction of where the pixel moved and the magnitude of movement.
This allows us to take information detected from the First Frame and propagate it forward. - This is extremely slow for ‘Colouring book annotation’ (90 Minutes for 1 image).
- FlowNetS-stacks two images as input.
- FlowNetC-convolute separately, combine with correlation layer.
Challenge: Segmentation of images through time.
FlowNet 2 2016:

- Combines FlowNetC and FlowNetS
- Produces smoother flow field.
- Preserves fine motion detail.
- Runs at 8–140fps.
- Process:
- Stacking Networks as an approach.
- Ordering of Dataset matters
SegFuse
Dataset:

- Original video of driving in 1080p in a 8k 360 degree video.
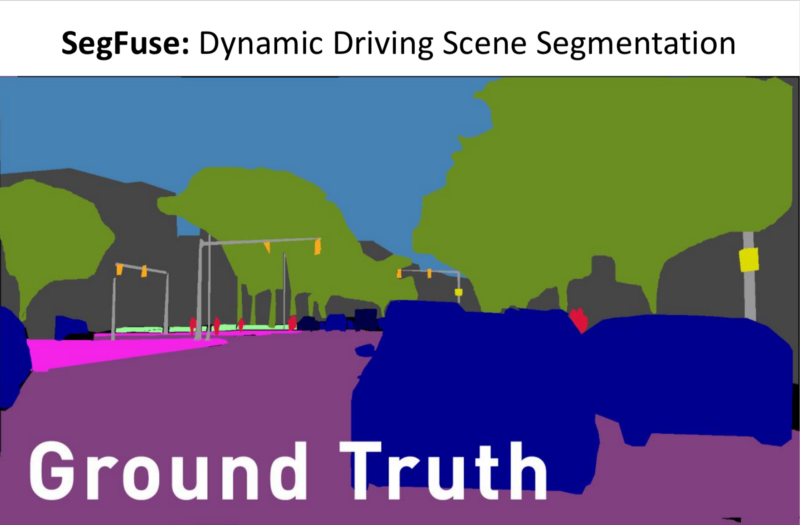
- Ground Truth for the Training Set, for every single frame.
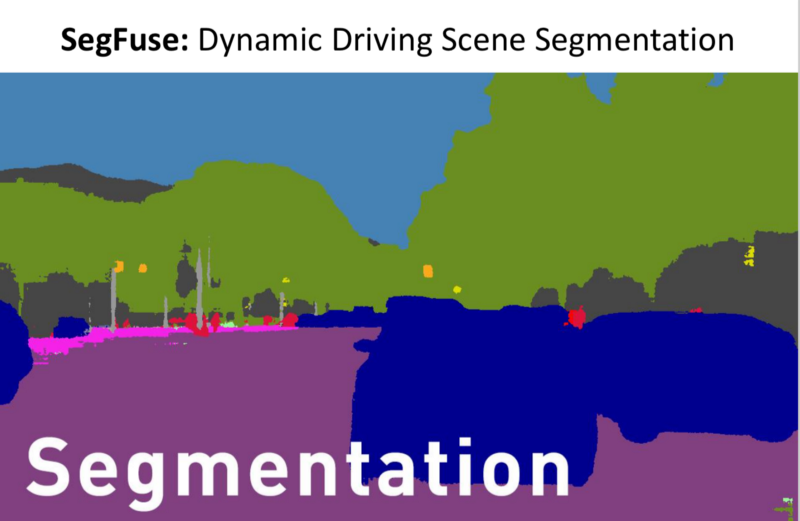
- Output of the SOTA Segmentation
- Optical Flow
Task:
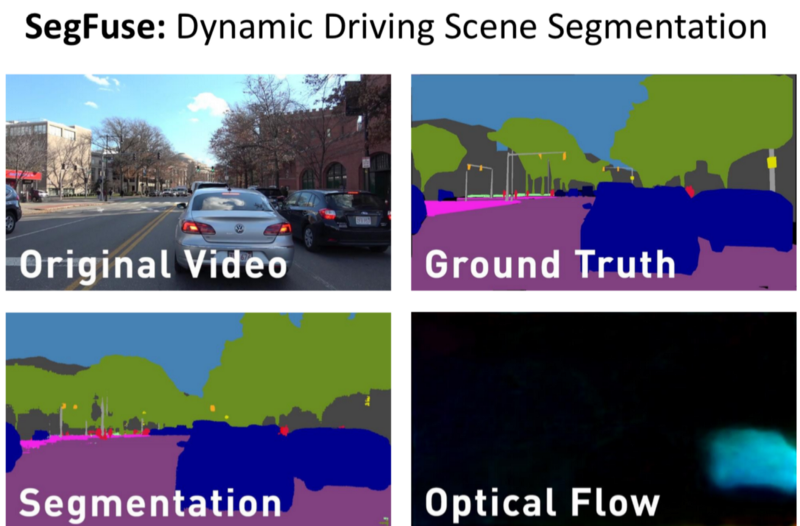
- Use the original video, ground truth, segmentation from a SOTA Network and improve the segmentation.
- Use output of the Network to help propagate the information better.
Can we figure out ways to use Temporal Information?
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science