
A brief summary of the PTDC ’18: PyTorch 1.0 Preview and Promise
You can find me on twitter @bhutanisanyam1
Note: All Images are from the Conference’s livestream
The PyTorch Developer Conference ’18 was really about the promise and future of PyTorch framework.

It also marked the release of the Framework’s 1.0 Preview version, along with many other cool frameworks built on Top of it.
FastAI_v1, GPytorch were released in Sync with the Framework, the majority of the big cloud providers announced their complete feature-wide support for the Framework.
The conference events featured cutting-edge researchers who spoke about their recent publications to practitioners and representatives of industries announcing their partnerships and support for the framework.
Most importantly, there was a brief but nice touch upon the future of AI itself as well as the framework.
The complete conference was about how PyTorch serves a wide variety of people: from Cutting Edge researchers to Practitioners to Educators. Even the lead dev(s) of the framework were eager about the community feedback and the preview release in itself is a promise of PyTorch to the community: the release of most needed features and a mark on the future growth.
It was all about the promise of the “1.0” release version which this article covers briefly.
PyTorch 1.0

In just the two years since it’s inception, the framework has grown humoungously to one of the most loved frameworks.
I would qoute Andrej Karpathy, “When PyTorch came out it was kind of like love at first sight and we’ve been happy together ever since.” which is really the experience that I share with the large community of users.
We already love the framework for its “Pythonic” nature (Eager mode) and ease of use. We’ve witnessed the wide known adoption of it amongst the reseach community and now the focus is really towards making it a better experience for production as well.
The current (pre-1.0) scenario if we’re to put code into production is:

PyTorch Prototype Code -> Exported to ONNX -> Deployed with Caffe2
Facebook has been using this approach internally, even though the post 2 steps are automated, the better way is again how do we short-circuit the last two steps.
PyTorch 1.0 eats up the last two steps and this problem is solved by writing it once, and shipping the code in the same framework. The prototype to deployment task is all handled in house with just one framework.
The challenges that need to be addressed for this approach to be useful are:
- Write Code once:
Re-writing in another framework shouldn’t be needed, neither re-optimisation. - The Performance throughput should be as per the expectations.
- Language Support: C++ is much more production friendly and really necessary when there’s an existing low latency requirement.
- Scaling: How do we scale efficiently across multiple “nodes” and “workers”.
Major Announcements:
Torch.jit
With the 1.0 release, the new PyTorch compiler aimed to help with deploying code into production was announced.
Earlier, the code was the model and it needed a Python VM to be deployed and run.
JIT will allow you to custom annotate your code and then export, save it to disk as a C++ runtime, to help fast execution of large code stacks.
JIT can inspect code ahead of time, on the fly/during execution, fusing a few graph nodes together and generating new code to allow efficient use of time and memory efficiently. On larger programs, this would allow a speedup of upto 20–30% time.
Production challenges:
PyTorch allows a “switch”/opt-in based change which would allow you to extensively prototype and only opt-in for the features when you’re working with constraints of a production environment.
Constraints from production:
- Hardware efficiency: you want to minimize the latency.
1.0 will feature faster execution for simple operation on Tensors and better exposure to best features of Caffe2.
ONNX connectivity: to enable better optimization for target platforms: mobile, embedded, etc.
Going forward, it’ll be easier to optimize chunks of the model instead of the complete model (future releases) - Scalability:
Distributed backend has been completely re-vamped. - C++ Deployment:
For smaller models or hyper-threaded requirements or embedded or low-latency requirement, C++ is a necessity.
1.0 will allow exporting only parts of code that are needed for deployment and can run in C++.
Support for Float16 and int8 accuracy will be released. Some libraries will be open sourced.
Mobile Deployment: For the vast world of mobile devices and architectures, the Caffe2go system used natively by Facebook for mobile devices will be fused into PyTorch for convenient deployment.
Script Model
This aims to address the shortcomings of Eager mode that make it hard to be deployed.
In Script Model, the code is written as subset of Python and it contains all the necessary features but restricts the dynamic features of Python making it hard for deployment.
You can annotate your code to allow the “eager” code to be run as “script code”. This is again a two way stream, you can always go back and make changes to orignal code.
- Tracing: You can trace the execution of your code to allow re-use of eager mode. It records what is run and allows running your code without Python present.
- Scripting:
You can annotate your code with @torch.jit.script and thus writing your code as a ‘script’ without using another language.
Control flow remains preserved, print statements can be used for debugging, you may even remove the annotation for debugging.
This can be saved to disk and run as a completely self contained archive to run the inference. You may even use C++ to interface with it.
You can also mix script and trace to allow maximum flexibility.
Note: Preview release allows a bunch of functions for script, the complete features support will come with the actual release.
C++ API

1.0 will allow a two way pathway from Python to C++ and backwards (for debugging and re-factoring reasons)
PyTorch’s foundation is ATEN, AUTOGRAD. C++ API allow you to extend these into PyTorch and even write custom implementations.
C++ Extensions also allow you to write custom calls to third party functions. This creates a python module but creates a C++ function and exposes it to python as a module, which too can be seamlessly written.
JIT allows you to integrate it into code and load it, compile it and serve it directly.
You can load this into your server or as a script and send it to production.
C++ Frontend:
In use cases where integrating python is painful, the C++ frontend(beta) was announced.
The only tradeoff being very minor differences except knowing the syntax difference.
The simple goal being allowing convinient porting from Python to C++.
Distributed Training
The goal is to use more resources to allow speed up by parallezing the tasks. However, since a lot of communication is involved, that might cause a problem.
1.0 has a new performance driven asunchronous backend aimed at performance: C10D. From Frontend to the distributed data parallel. It also promises near the roof performance on both single and multi node cases.
C10D Overview:
- C10D has three backends: Gloo, NCCL, MPI
- Fully async for all three backends.
- Both Python and C++ APIs.
- Performance optimization.
- Upcoming releases will feature fault taulerence for cases such as where a node dies without affecting your training.
1.0 will feature complete backward compatibility for sync and async modes.
Distributed Data Parallel: Backed up with C10D library which allows fast parallel training with some decent optimizations with steps such as overlapping reductions and coalesing tensors to potentially improve performance.
Deploying to Production
The second session was about FAIR’s research and how PyTorch fits into the picture and how it will now replace Caffe2 for all of their internal deployment requirements.
PTDC featured a demo of Fairseq: An open source machine translation tool
This was awarded #1 WMT’18 by humans in comparision with many other models.
PyTorch Translate: Another great open source projects which showcases the path from Research to Production, why and how its deployed by facebook across its various use-cases.
The promise of PyTorch holds true for this use-case and enables flexible prototyping. The current 3 step pipeline was used, the future will feature an end to end PyTorch framework along with integrated C++ API and Exporting Beam search.
PyText: PyText allows an easy research and path to production for facebook.
An example demo: Facebook deploys Python Services to allow interfacing with the messanger bots which run the models.
Another great future looking project was demoed: LipSync for Occulus where the team wants to create use cases for animated avatars which will the basis of interactions when working with AR.
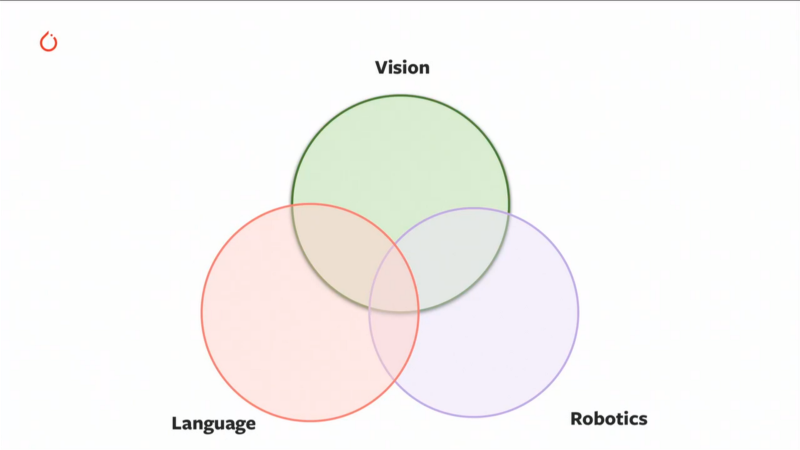
Embodied intelligence: A great future looking case where the argument made was: “We need to think of Intelligence as a process which combines Vision, Langauge and Robotics” with an example of a robot navigating in house and answering questions such as:
"What colour is the Car?
Finally, an overview of Opendgo and its great results was showcased, all of which is also based on PyTorch with the help of ELF, Distributed ELF.
Cloud
AWS:
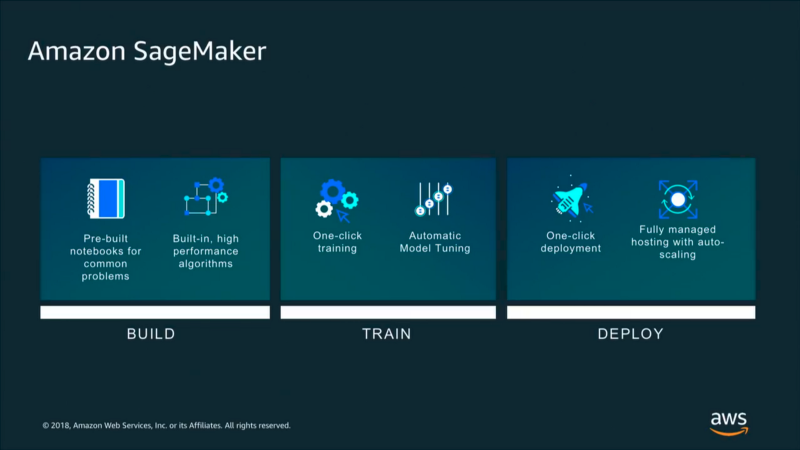
Amazon SamgeMaker features PyTorch 1.0 images and will allow easy running of distributed training.
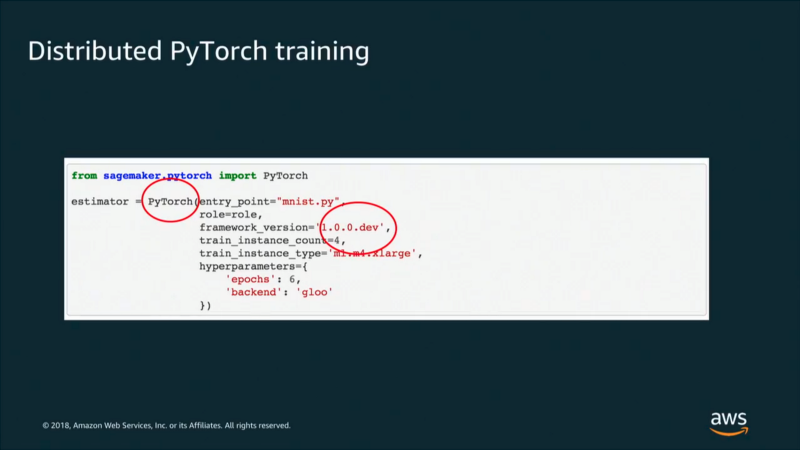
You can package your code as a docker container: host it, deploy it for inference.

Microsoft:

Microsoft really showed their love for PyTorch by announcing a few major promises and investments:
- A dedicated Team working to improve PyTorch.
- Working closely with the PyTorch community.
- Contributing to the GitHub Code.
- Bringing extensive windows support.
Microsoft also declared that they have integrated PyTorch into all of their ML Products:
- VS Code
- Azure
- Data Science VM
- Azure ML
GCP:
Google Cloud also allowed a few major announcenments in partnership with 1.0 release:
- 1.0 preview VM launch
- Kubeflow enabled with PyTorch.
- Tensorboard support

- TPU Support: Cloud TPU, TPU pods with support for easy upscaling.
Academic

The following research from academia were showcased, all of which have a PyTorch implementation:
- SignSGD: Solving distributed training bottlnecks.
- Tensorly: High-Level API for Tensor algebra.
- CAST (CALTECH): Neural Lander- Using NN for better landing of drones.
- BAIR (UC Berkley):
“Pixels in, Pixels Out”:
-CycleGAN
-Pix2Pix
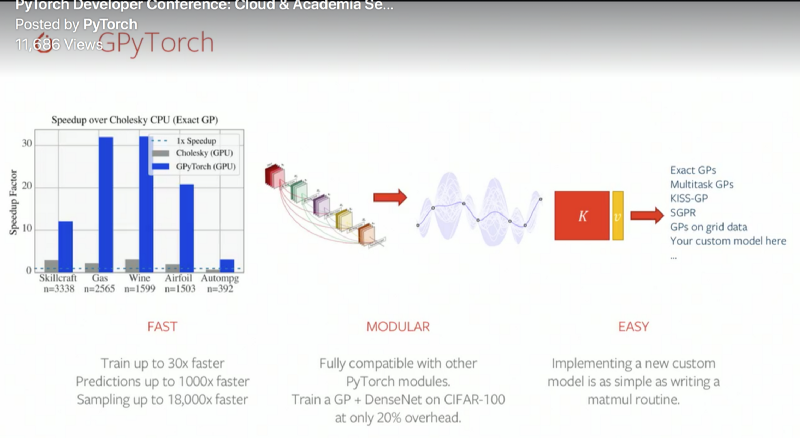
- Cornell University:
- Stochastic Weight Averaging
- Scalable Gaussian Processes
- GPyTorch: Gaussian Processes in PyTorch (Cutting edge release is out) with some cool features such as BlackBox Linear Algebra, LazyTensor. - CMU: QPTH:
Solving Complex differentiable layers in Deep Learning.
- Optnet
- MPC - NYU: Deep EHR: Chronic prediction using medocal nodes all open source models. Intersection of NLP, Medical, DL world.
Enterprise:
Nvidia:
Nvidia did a few cool demos of their research based on PyTorch:
- DL Supersampling
- Vid2Vid
- Edge to faces
- Pose to People
- Frame Prediction
- Unsupervised Language Model
Salesforce:
Salesforce showcased their efforts of decaNLP: A benchmark, framework and an approach for mutiple problems posed by text.
Uber AI:
Uber AI showcased PyroAI: a PyTorch based “Deep universal probabilistic programming langauge”
AllenNLP:
An Open Source Library for Deep Learning with NLP.
PyTorch in Education
In the final talks, Udacity and fast.ai spoke about why PyTorch is their framework of choice and how they hope to revolutinise Deep Learning education with it.
“You don’t have to Teach PyTorch and its syntaxes, you can just focus on the more important concepts without worrying”
-Udacity
“Many cutting edge implementations aren’t just possible in Keras. We’ve loved PyTorch since its initial releases”
-FastAI
Summary
PyTorch has always been a community driven approach and the 1.0 release really showcased their dedication and the promise it holds for the community.
The Script Mode, JIT Compiler all retain the native “flexibility” and allow production ready-ness. C++ Frontend and use-cases, distributed training both in the 1.0 and its upcoming releases are really a step towards a mature framework.
PyTorch 1.0 will remain the same flexible framework at its heart with the eager mode prototyping and will feature convinient production ready features such as Script mode and a C++ Frontend for the entire use-cases out there.
Things I’m excited about:
- Official 1.0 release: The release is announced to happen Pre-NIPS conference which puts it somewhere before December.
- TF Vs PyTorch:
Its amazing to see how both the frameworks are converging to a similar pathway.
Even though TF is the widely deployed one, the promise of 1.0 is a serious challenge to TF and it’ll be great to see how the release of TF 2.0 sets things for the future of both frameworks. - Finally, I’m excited about the 1.0 official release and FastAI V_1 release: Fast.ai is always at the cutting edge and is already sitting on top of the 1.0 preview version, I can’t wait for the MOOC’s live version to get started.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science
