

You can find me on twitter @bhutanisanyam1
During ‘Training’ of a Deep Learning Model, we backpropogate our Gradients through the Network’s layers.
During experimentation, once the gradient value grows extremely large, it causes an overflow (i.e. NaN) which is easily detectable at runtime or in a less extreme situation, the Model starts overshooting past our Minima; this issue is called the Gradient Explosion Problem.
This is when they get exponentially large from being multiplied by numbers larger than 1, consider the example:
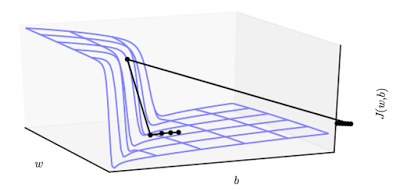
Gradient clipping will ‘clip’ the gradients or cap them to a Threshold value to prevent the gradients from getting too large.
In the above image, Gradient is clipped from Overshooting and our cost function follows the Dotted values rather than its original trajectory.
L2 Norm Clipping
There exist various ways to perform gradient clipping, but the a common one is to normalize the gradients of a parameter vector when its L2 norm exceeds a certain threshold:
new_gradients = gradients * threshold / l2_norm(gradients)
We can do this in Tensorflow using the Function
tf.clip_by_norm(t, clip_norm, axes=None, name=None)This normalises t so that its L2-norm is less than or equal to clip_norm
This operation is typically used to clip gradients before applying them with an optimizer.
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science