
You can find me on twitter @bhutanisanyam1, where I talk/share/tweet all about ML, fastai and Kaggle
Unofficial Notes for the Lecture #1 of the fast.ai 2020 course
Note: All of the images are from the lecture.
Note: I've used an acronym TJSTD for: Things Jeremy Says to do
Introduction
fast.ai 2020:
The v-4/2020 course is going to be the "definitive version" of the course:
- It's in sync with the FastBook release
- There is a Peer-Reviewed Paper
- There is a re-write of the library from scratch
The syllabus is based very closely on the book, you may access the notebooks for free-the notebook was made based on jupyter notebooks.
Note: You can read it for free, but it might be lesser convenient than reading on a kindle/paper-please don't convert it into a book! If you'd like to do that, please consider purchasing the book!
Frequently incorrectly asked questions about DL:

- Are you too stupid for DL?
- How many GPUs do you need for DL?
- Do you need a PhD?
A lot of world class research projects and work has come out of the fastai students based on a single GPU, using "small data" or without a "traditional background".
Okay, What do you need? Pre-requisites?
- You need 1 year of coding experience, preferably in Python.
TJSTD: Stick with it, it's easy to pick up things with practise.
Q: Where is deep learning the best known approach?

In many of these cases, its equivalent to some definition of human performance.
Note: Try to type the keyword and deep learning in google and find many papers, etc.
History:
- Deep Learning is based on types of neural nets.
- MK-1 perceptron appeared at Cornell.
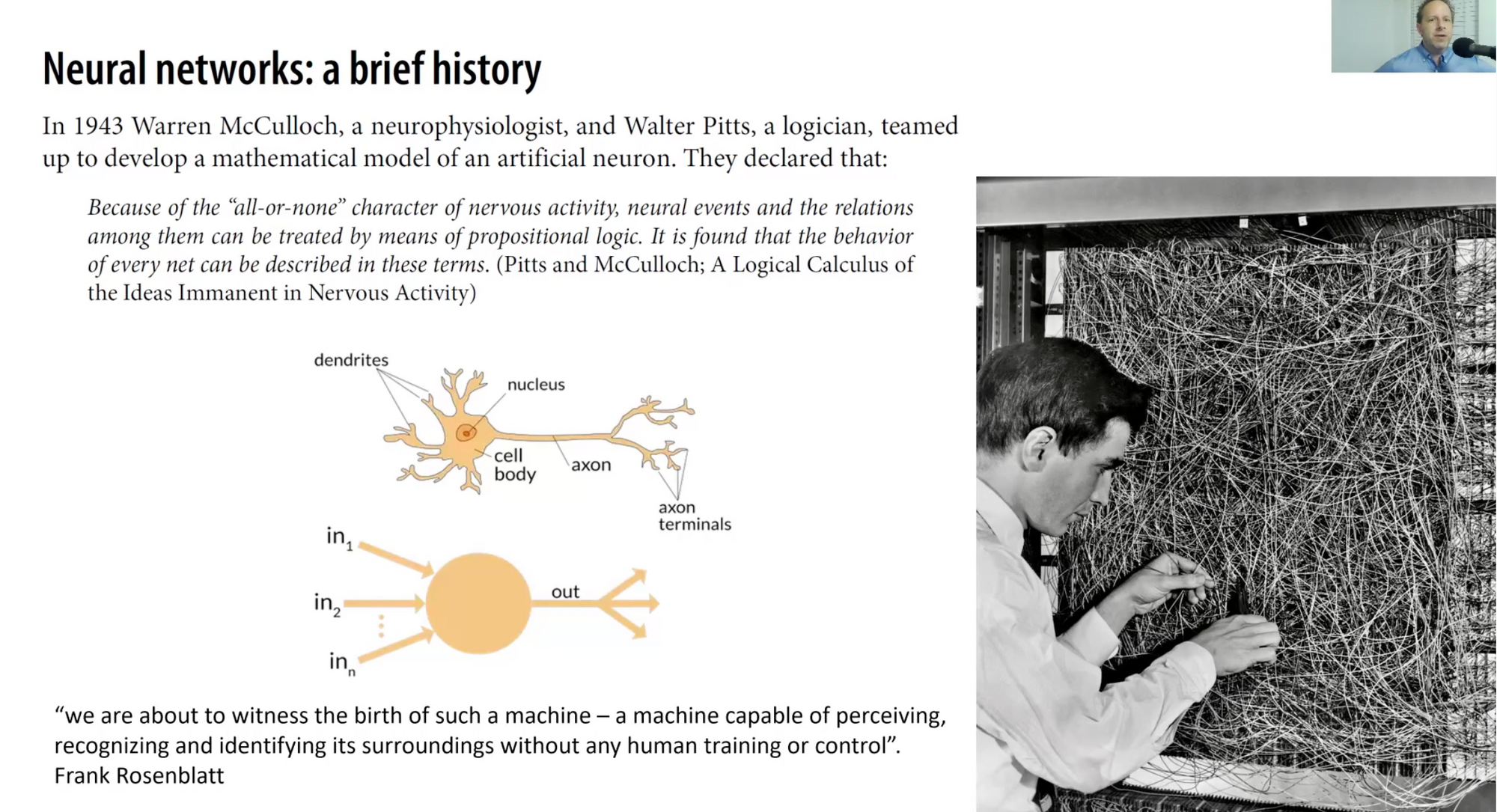
The First AI Winter
This happened strongly since a professor pointed out that a single layer of a NN cannot learn a simple function and this caused an AI Winter.

MIT released PDP:
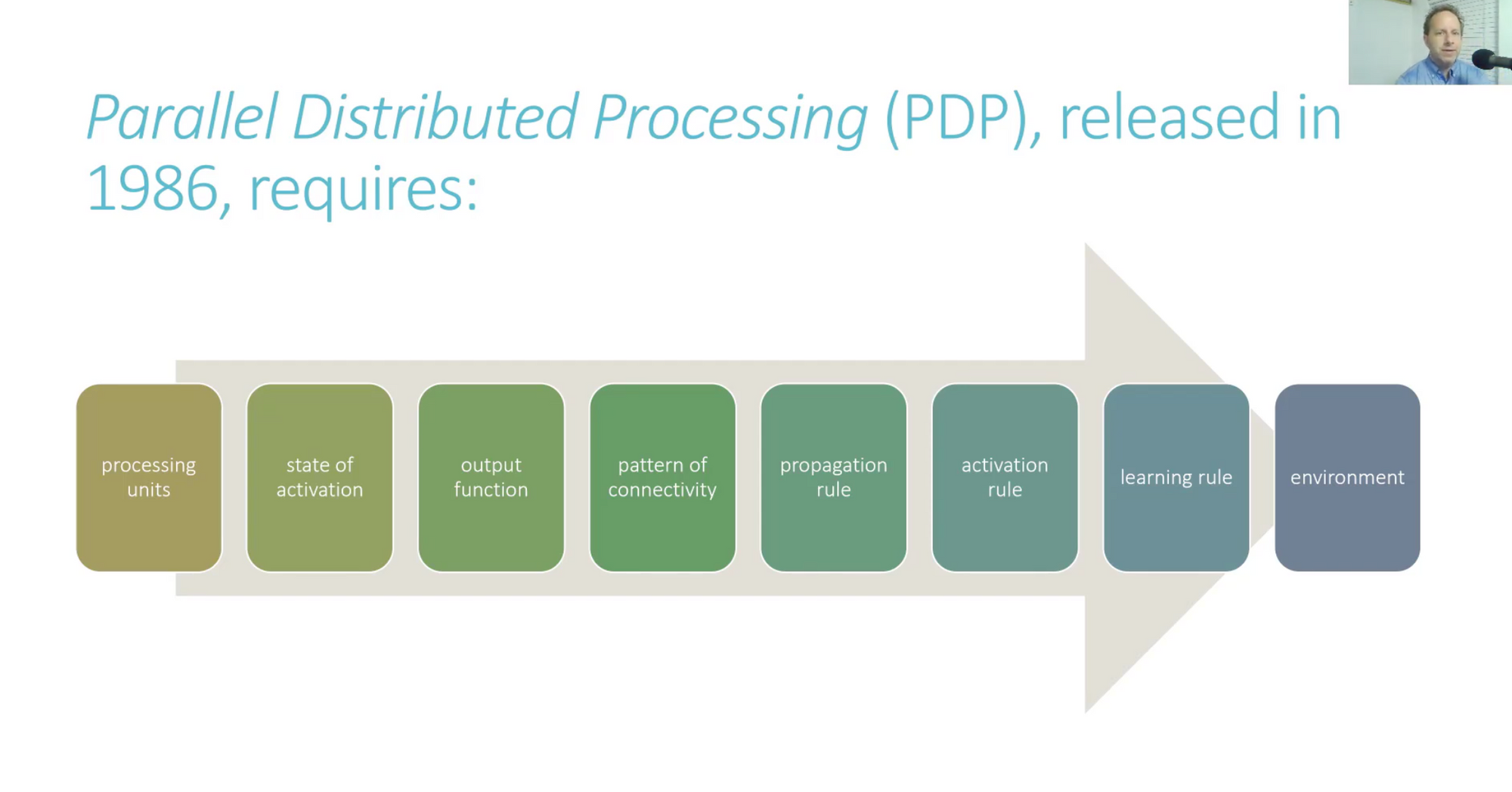
Note: Come back and look at this picture, everything we're learning is basically can be mapped to PDP.
Return of DL:

At that time, researchers had shown as you add layers you get better performance and now we have NNs reaching their potential.
The fast.ai Learning Philosophy:
"We're not going to start with a 2 hour lecture on sigmoid"
Or a Refresher on calculus
Based on the work of David Perkins and similar people working on the idea of "Playing the whole game": If you're going to teach someone baseball, you don't teach them the basics of everything, etc and then 20 years later you let them play a game-which is kind of how Math education works right now.

- From Step #1: You have a sense of the whole game/the complete idea.
- Step #2: Make the game worth playing: Keep a score, have a LB! Make it engaging/interesting. Making sure, the thing you're doing, you're proving context and interest.
For the fast.ai approach, what this means is: we're going to train models end to end and they will be SOTA world class models from Day #1 and you'll do that as homework as well!
- Step #3: Work on the hard parts! Idea: Practise.
TJSTD: Don't just swing a bat at the ball, and "muck around"-find the bit where you're least good at. In DL, we do not dumb things down-by the end of the course, you'd have done the calculus/Lin algebra/Software.
We will be doing the hard part first-practising the thing and then we can understand the hard part-you'll know why you need something.
This will feel weird. Don't spend too much time studying theory-train models, and code!
fast.ai Software Stack:
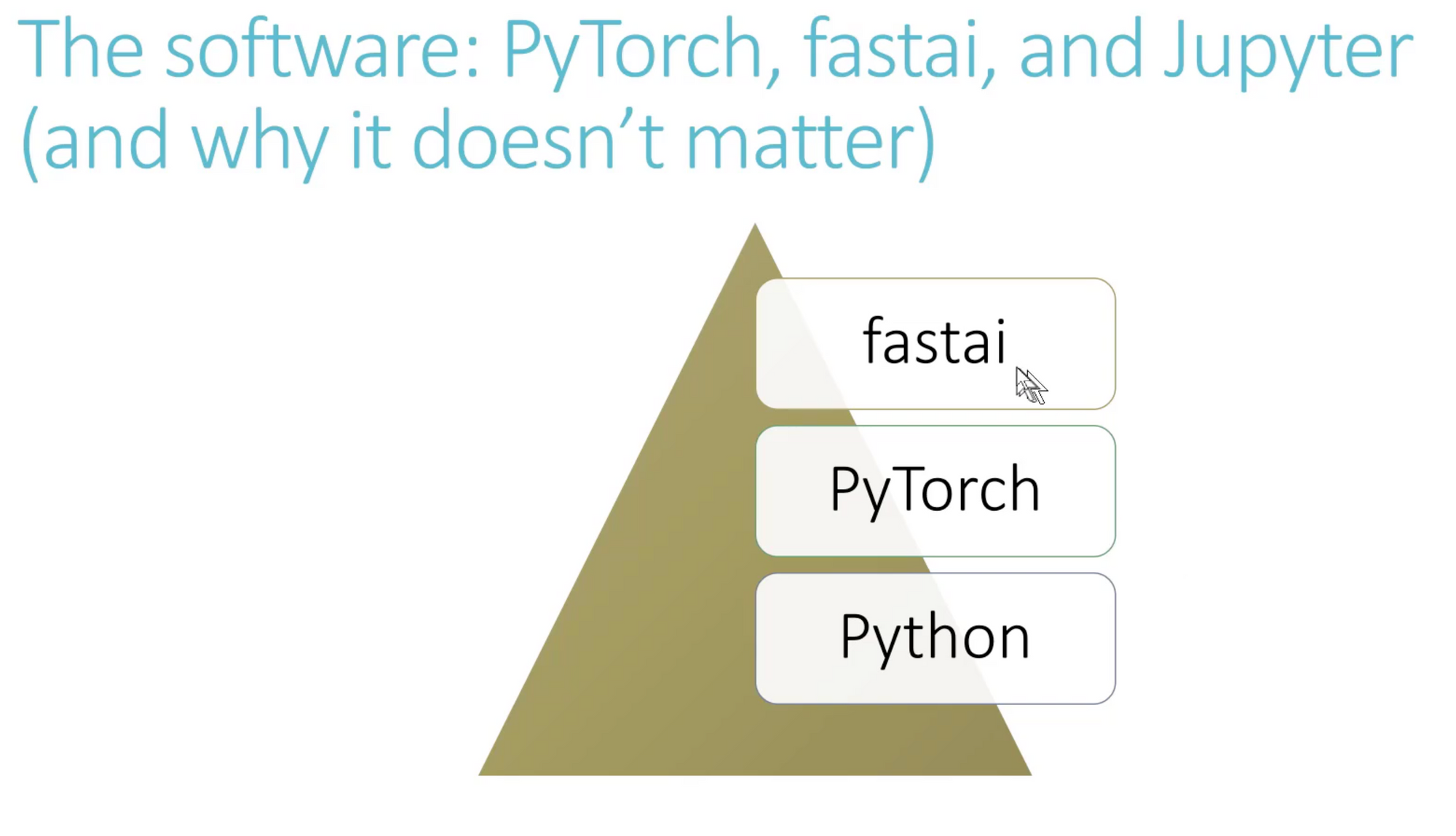
- Python is very expressive and flexible. The vast majority of the community uses it.
- PyTorch and TF are the 2 libraries that most folks use today. There has been a great switch recently by the community from TF to PyTorch thanks to the ease of use & flexibility.
- PyTorch: Super-Flexible and Dev friendliness but it's not beginner friendly and there are no "higher level" APIs. There's no easy way to build stuff quickly using PyTorch.
- fastai: Most Popular Higher level API for PyTorch, it's not just designed for beginners and teaching, as well as for industry and practitioners.
This is achieved by making it a layered API-for SE, this won't be unusual. This follows practises that no library uses in DL-decoupling and refactoring.
TJSTD: It actually doesn't matter what stack you learn, you should be able to switch in under a week-the important thing is to learn the concepts. By using an API that minimises the boiler plate code, you can focus on the concepts.
Setting up a GPU Server
It's a huge distraction to be doing sysadmin work setting up a GPU, please use Linux! It's hard enough to learn DL, don't increase the burden with making it more difficult. Please use the available options.
Remember to shutdown the instance! Closing the browser!=Closing the instance.
Link to forums-setup help thread.
Launching Notebooks
After you're done setting up, you'll find yourself at this page.

About Jupyter: This is a REPL, it allows you to put headings, multimedia, graphics. It's one of the most widely used ones outside of shells.
The ENTIRE library and book has been written in this. Expect it to feel different!
How it works: You can see an interface to a server that is running on an instance.
Jupyter mode:
- Edit Mode:
- Command Mode: Allows you to run command.
Allows you to write Markdown-it's super handy and you need it for Jupyter.
Ex: The book notebooks have all kinds of formattings, etc.
You can also Launch a Terminal from the jupyter server: Note you don't need to know how to launch a terminal.
Pro-Tip: Duplicate Notebooks when you're running an experiment.
TJSTD: Do the questions! Rather than a summary, the book has a questionnare to do the same thing. If you don't get a question, come back to it later.
It's okay to get stuck, skip forward and come back since things are explained in different formats throughout the book and course.
Running the first notebook
#1 Shortcut: Shift + enter to run a cell.
Note: Don't expect exact same results, there is some randomness.
Note: If it takes > 5 minutes, that's a bad sign! Figure out if there is something wrong.
Note: Don't worry if you don't know the whole code yet, we're just seeing what it does.
What's going on here?
TJSTD: Best to run the code and see what happens 😉
These kinds of models can learn only from the information provided.
Note: Sometimes the visualisation code is hidden/explained. You can ignore it.
Deep Learning & What is ML?
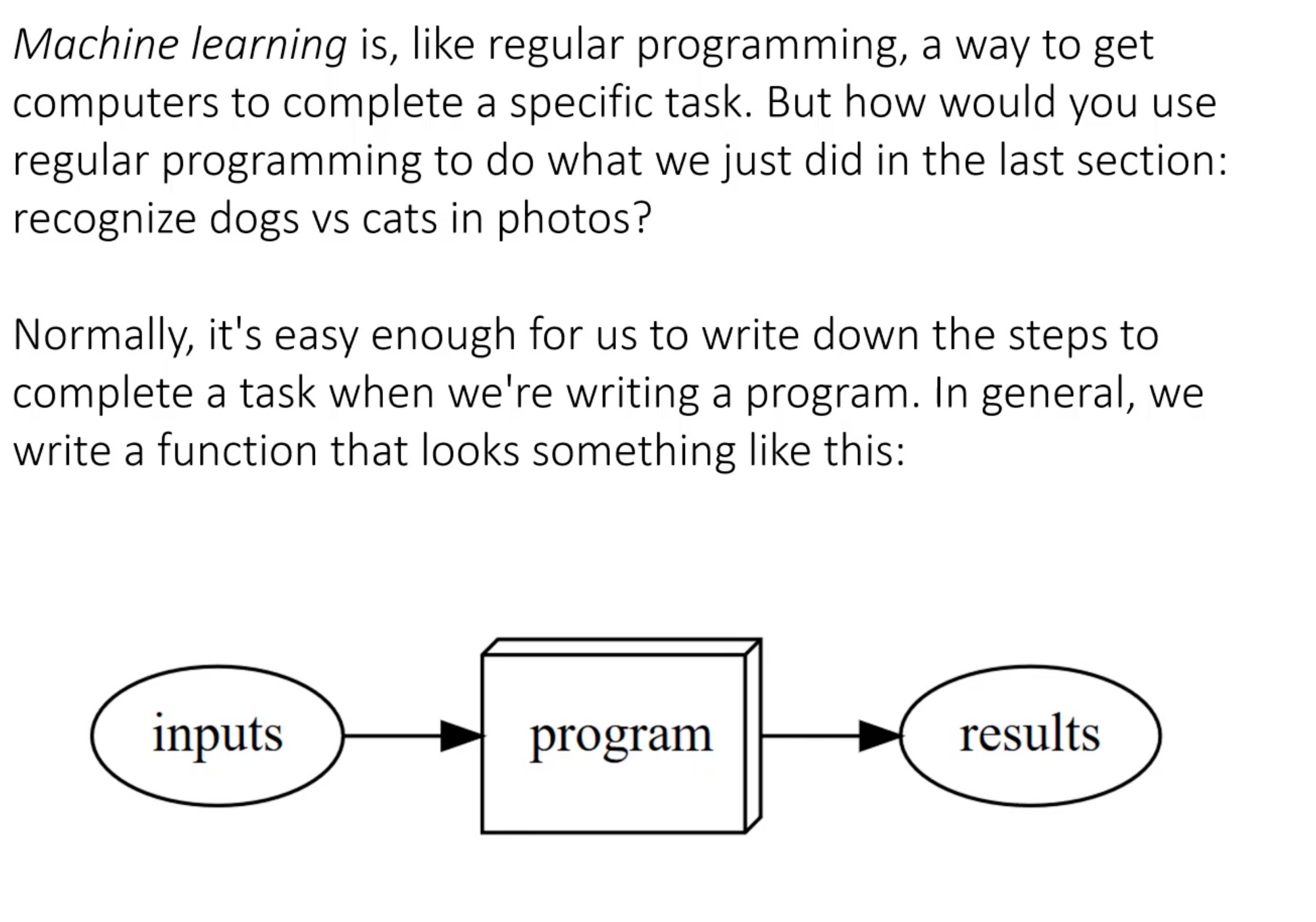
The general idea of a program where we write the instructions doesn't work well for visualisation. In 1962, Arthur Samuel described the problem and his approach:

The basic idea is, the "Model" doesn't only produce output based on input, but also based on some set of weights/parameters that describe how the model is supposed to work.
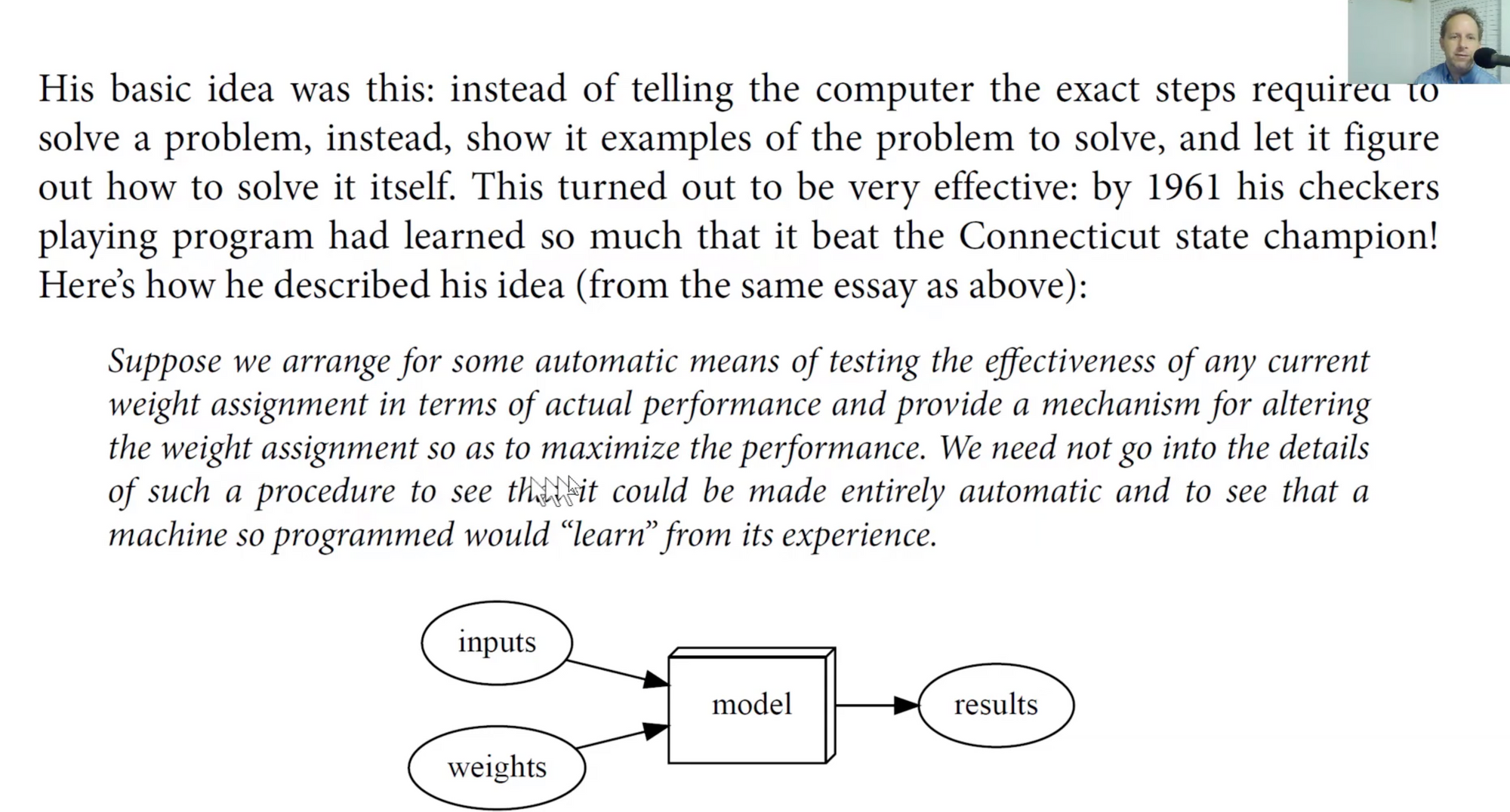
If we can describe all of the possible states, for ex. of checkers and then if we had a way of checking how effective current weight assignment is for winning/losing and then if we can alter the weights and find a better way to do the weight changes. We can then automate the process.

A way of creating programs such that they learn rather than they can program.

After we've run it for a while, we have a set of weights that are good. Now we can replace the program with a "model".
Using a trained model as a program to do a task is known as inference.
How would you do for Image Recognition?

We want some function in the model that is a very flexible-enough that there is a set of weight that can cause it do anything-this is a NN.
Note: This Math function will be described later. To use it, it doesn't matter what the function is.
Universal Approximation Theorem applies to NN, if you just find the right weights, that they can solve any problems.

Q: How do we do this?
We use a way of updating the weights to "train the NN":
SGD: Stochastic Gradient Descent
A way of updating "weights". Note: We'll take a closer look later.
Neither NNs or SGD are complex-they are nearly entirely addition/multiplication. The catch is there's a lot of them-impossible for us to mentally visualise them.
DL Terms:
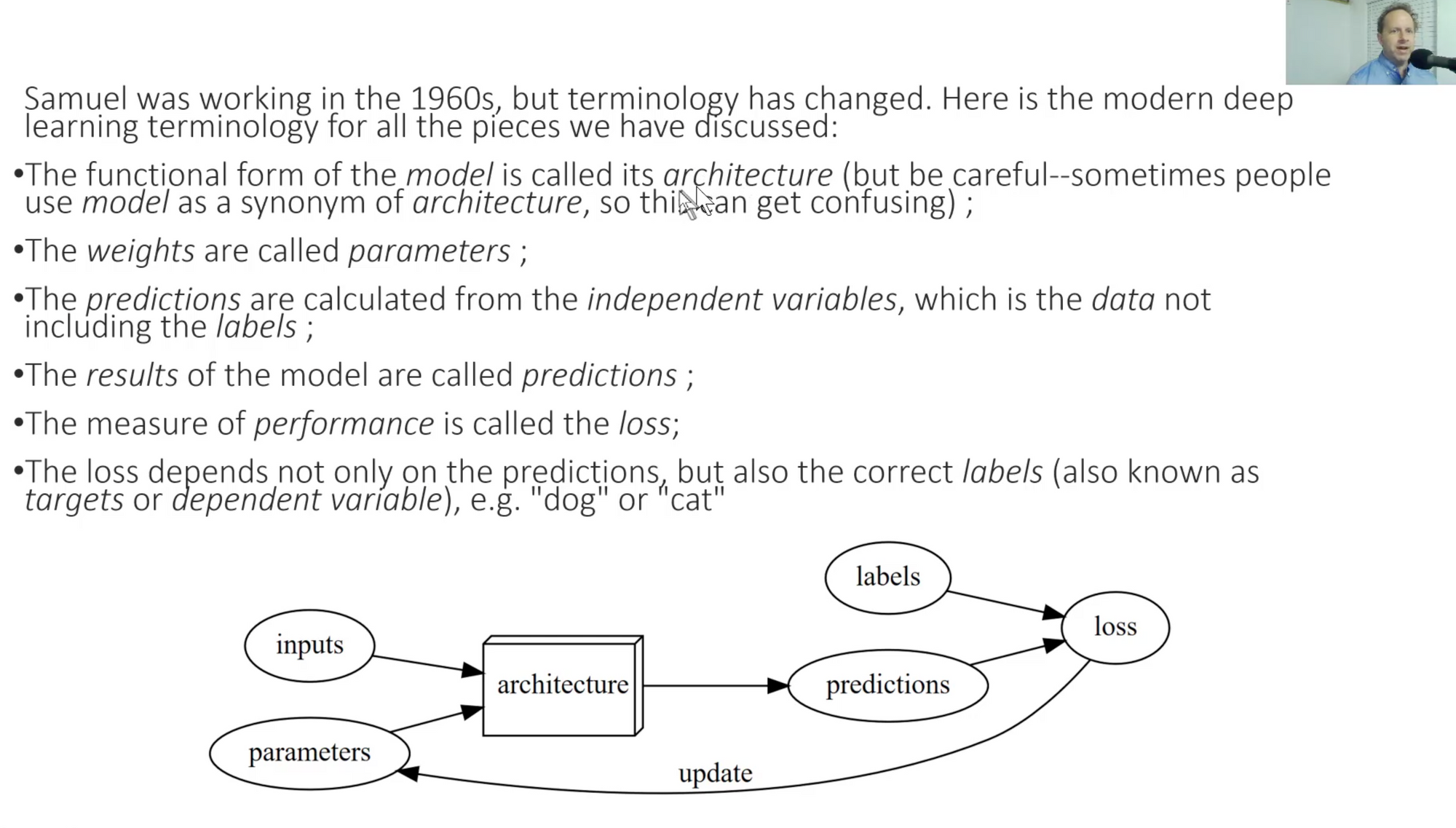
- Architecture
- Parameters (Not weights)
- Predictions: Things that come out of the model. These are based on independent and dependent variables.
- Loss: Measure of performance
DL is not magic: Limitations to ML

Note: Often times when organisations say that they don't have "enough data", they mean that they don't have enough "Labelled" Data. Since most of the times they are trying to automate a task that they are already working on, so by definition they have a lot of data. It's just not labelled data.
Ex: It's easy to get data for medical images but it's tricky to label them in the right fashion that can be captured in a structured matter.
How a model interacts with it's environment

Note: Your model might introduce a +ve feedback loop. In cases where you have a bias in your data, this leads to more bias being added.
What's going on in the 6 lines of code?
In python you can't use an external library until you import from it. Normally in Python, people just import functions and classes that you need. You can also do a * to import everything.
TJSTD: This might be a VERY bad idea, since this causes importing not just every module but also the modules it depends on.
For fastai: It's designed to enable very rapid prototyping hence the authors have been very thoughtful of allowing this without causing a disaster.
It's upto you, but be assured, this won't cause problems within the framework.
Structure/Design of the API:
fastai.X is used to cover an application that fastai supports. These are mainly 4:
- Vision
- Tabular
- Collaborative
- Text/NLP.
You can import all possible important applications related to something by doing: from fastai2.X.all import *
TJSTD: How do you find details about a fn when you import *?
Paste it into a cell and Shift Enter
You can call a doc() function to call the documentation. It can also show in docs-to the full documentation, where you have examples, tutorials.
Note: All of this was made ENTIRELY in notebooks.
untar_data(): Downloads a data, decompresses and loads it into a variable. fastai has access to many important datasets via URL and returns the Path.
TODO: Link writeup/discussions about this.
Next step is to tell the type of data to the model: untar_data() returns the path, we need to tell which images are in the path.
How do you tell if each image is a cat or dog?
The creators decided to keep the first letter of cats capital.
Next thing after we've told where the data is-we create a learner.
Learner is passed the data, architecture-Resnets are a super great starting point. What things you want to point out: Error_rate for this case.
Then we call fine_tune() which does the training.
Error_Rate() is always calculated on data which is not being trained with.
We want to avoid overfitting, hence we use a validation dataset.
TODO: Link article by Rachel.
TJSTD: The craft of doing DL is all about creating a model that has a proper fit. The only way you know a model has a proper fit is being seeing it perform on a data that was not used to train it. So we always set aside some data to create a validation data set.
Try: Comparing model against the following problems and appreciate the similarity for the pipeline.
- Segmentation model
- Text Classification
- Tabular Data
- Collab Filtering

The same basic code and the same basic SE and Math concepts allow us to do VASTLY different tasks. Reason: The underlying definition of ML-if you can find a way to parameterise weights and update them, you can create models to perform predictions.
TSTD:
- Make sure you can spin up a GPU Server
- See the code and understand how it works, use the doc function
- Do some searching in docs
- See if you can run the docs
- Try to get comfortable and try to find your way around
- Don't move on until you can run the code.
- Read the chapter of the book
- Go through the questionnaire.
- Try to do all the parts based on what we have learned so far
You can find me on twitter @bhutanisanyam1
Subscribe to my Newsletter for updates on my new posts and interviews with My Machine Learning heroes and Chai Time Data Science